forked from Github/frigate
Compare commits
4 Commits
v0.6.0-rc1
...
person_fil
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
a7d68a4998 | ||
|
|
03e46efcdd | ||
|
|
27e39edd65 | ||
|
|
4f829e818e |
@@ -1,6 +1 @@
|
||||
README.md
|
||||
diagram.png
|
||||
.gitignore
|
||||
debug
|
||||
config/
|
||||
*.pyc
|
||||
README.md
|
||||
1
.github/FUNDING.yml
vendored
1
.github/FUNDING.yml
vendored
@@ -1 +0,0 @@
|
||||
github: blakeblackshear
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -1,4 +1,2 @@
|
||||
*.pyc
|
||||
debug
|
||||
.vscode
|
||||
config/config.yml
|
||||
149
Dockerfile
Executable file → Normal file
149
Dockerfile
Executable file → Normal file
@@ -1,60 +1,107 @@
|
||||
FROM ubuntu:18.04
|
||||
LABEL maintainer "blakeb@blakeshome.com"
|
||||
FROM ubuntu:16.04
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
# Install packages for apt repo
|
||||
RUN apt -qq update && apt -qq install --no-install-recommends -y \
|
||||
software-properties-common \
|
||||
# apt-transport-https ca-certificates \
|
||||
build-essential \
|
||||
gnupg wget unzip tzdata \
|
||||
# libcap-dev \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa -y \
|
||||
&& apt -qq install --no-install-recommends -y \
|
||||
python3.7 \
|
||||
python3.7-dev \
|
||||
python3-pip \
|
||||
ffmpeg \
|
||||
# VAAPI drivers for Intel hardware accel
|
||||
libva-drm2 libva2 i965-va-driver vainfo \
|
||||
&& python3.7 -m pip install -U wheel setuptools \
|
||||
&& python3.7 -m pip install -U \
|
||||
opencv-python-headless \
|
||||
# python-prctl \
|
||||
numpy \
|
||||
imutils \
|
||||
scipy \
|
||||
psutil \
|
||||
&& python3.7 -m pip install -U \
|
||||
Flask \
|
||||
paho-mqtt \
|
||||
PyYAML \
|
||||
matplotlib \
|
||||
pyarrow \
|
||||
&& echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" > /etc/apt/sources.list.d/coral-edgetpu.list \
|
||||
&& wget -q -O - https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - \
|
||||
&& apt -qq update \
|
||||
&& echo "libedgetpu1-max libedgetpu/accepted-eula boolean true" | debconf-set-selections \
|
||||
&& apt -qq install --no-install-recommends -y \
|
||||
libedgetpu1-max \
|
||||
## Tensorflow lite (python 3.7 only)
|
||||
&& wget -q https://dl.google.com/coral/python/tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& python3.7 -m pip install tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& rm tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& rm -rf /var/lib/apt/lists/* \
|
||||
&& (apt-get autoremove -y; apt-get autoclean -y)
|
||||
# Install system packages
|
||||
RUN apt-get -qq update && apt-get -qq install --no-install-recommends -y python3 \
|
||||
python3-dev \
|
||||
python-pil \
|
||||
python-lxml \
|
||||
python-tk \
|
||||
build-essential \
|
||||
cmake \
|
||||
git \
|
||||
libgtk2.0-dev \
|
||||
pkg-config \
|
||||
libavcodec-dev \
|
||||
libavformat-dev \
|
||||
libswscale-dev \
|
||||
libtbb2 \
|
||||
libtbb-dev \
|
||||
libjpeg-dev \
|
||||
libpng-dev \
|
||||
libtiff-dev \
|
||||
libjasper-dev \
|
||||
libdc1394-22-dev \
|
||||
x11-apps \
|
||||
wget \
|
||||
vim \
|
||||
ffmpeg \
|
||||
unzip \
|
||||
libusb-1.0-0-dev \
|
||||
python3-setuptools \
|
||||
python3-numpy \
|
||||
zlib1g-dev \
|
||||
libgoogle-glog-dev \
|
||||
swig \
|
||||
libunwind-dev \
|
||||
libc++-dev \
|
||||
libc++abi-dev \
|
||||
build-essential \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# get model and labels
|
||||
RUN wget -q https://github.com/google-coral/edgetpu/raw/master/test_data/ssd_mobilenet_v2_coco_quant_postprocess_edgetpu.tflite -O /edgetpu_model.tflite --trust-server-names
|
||||
RUN wget -q https://dl.google.com/coral/canned_models/coco_labels.txt -O /labelmap.txt --trust-server-names
|
||||
RUN wget -q https://github.com/google-coral/edgetpu/raw/master/test_data/ssd_mobilenet_v2_coco_quant_postprocess.tflite -O /cpu_model.tflite
|
||||
# Install core packages
|
||||
RUN wget -q -O /tmp/get-pip.py --no-check-certificate https://bootstrap.pypa.io/get-pip.py && python3 /tmp/get-pip.py
|
||||
RUN pip install -U pip \
|
||||
numpy \
|
||||
pillow \
|
||||
matplotlib \
|
||||
notebook \
|
||||
Flask \
|
||||
imutils \
|
||||
paho-mqtt \
|
||||
PyYAML
|
||||
|
||||
# Install tensorflow models object detection
|
||||
RUN GIT_SSL_NO_VERIFY=true git clone -q https://github.com/tensorflow/models /usr/local/lib/python3.5/dist-packages/tensorflow/models
|
||||
RUN wget -q -P /usr/local/src/ --no-check-certificate https://github.com/google/protobuf/releases/download/v3.5.1/protobuf-python-3.5.1.tar.gz
|
||||
|
||||
RUN mkdir /cache /clips
|
||||
# Download & build protobuf-python
|
||||
RUN cd /usr/local/src/ \
|
||||
&& tar xf protobuf-python-3.5.1.tar.gz \
|
||||
&& rm protobuf-python-3.5.1.tar.gz \
|
||||
&& cd /usr/local/src/protobuf-3.5.1/ \
|
||||
&& ./configure \
|
||||
&& make \
|
||||
&& make install \
|
||||
&& ldconfig \
|
||||
&& rm -rf /usr/local/src/protobuf-3.5.1/
|
||||
|
||||
# Download & build OpenCV
|
||||
RUN wget -q -P /usr/local/src/ --no-check-certificate https://github.com/opencv/opencv/archive/4.0.1.zip
|
||||
RUN cd /usr/local/src/ \
|
||||
&& unzip 4.0.1.zip \
|
||||
&& rm 4.0.1.zip \
|
||||
&& cd /usr/local/src/opencv-4.0.1/ \
|
||||
&& mkdir build \
|
||||
&& cd /usr/local/src/opencv-4.0.1/build \
|
||||
&& cmake -D CMAKE_INSTALL_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/ .. \
|
||||
&& make -j4 \
|
||||
&& make install \
|
||||
&& rm -rf /usr/local/src/opencv-4.0.1
|
||||
|
||||
# Download and install EdgeTPU libraries
|
||||
RUN wget -q -O edgetpu_api.tar.gz --no-check-certificate http://storage.googleapis.com/cloud-iot-edge-pretrained-models/edgetpu_api.tar.gz
|
||||
|
||||
RUN tar xzf edgetpu_api.tar.gz \
|
||||
&& cd python-tflite-source \
|
||||
&& cp -p libedgetpu/libedgetpu_x86_64.so /lib/x86_64-linux-gnu/libedgetpu.so \
|
||||
&& cp edgetpu/swig/compiled_so/_edgetpu_cpp_wrapper_x86_64.so edgetpu/swig/_edgetpu_cpp_wrapper.so \
|
||||
&& cp edgetpu/swig/compiled_so/edgetpu_cpp_wrapper.py edgetpu/swig/ \
|
||||
&& python3 setup.py develop --user
|
||||
|
||||
# Minimize image size
|
||||
RUN (apt-get autoremove -y; \
|
||||
apt-get autoclean -y)
|
||||
|
||||
# symlink the model and labels
|
||||
RUN ln -s /python-tflite-source/edgetpu/test_data/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite /frozen_inference_graph.pb
|
||||
RUN ln -s /python-tflite-source/edgetpu/test_data/coco_labels.txt /label_map.pbtext
|
||||
|
||||
# Set TF object detection available
|
||||
ENV PYTHONPATH "$PYTHONPATH:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research:/usr/local/lib/python3.5/dist-packages/tensorflow/models/research/slim"
|
||||
RUN cd /usr/local/lib/python3.5/dist-packages/tensorflow/models/research && protoc object_detection/protos/*.proto --python_out=.
|
||||
|
||||
WORKDIR /opt/frigate/
|
||||
ADD frigate frigate/
|
||||
COPY detect_objects.py .
|
||||
COPY benchmark.py .
|
||||
|
||||
CMD ["python3.7", "-u", "detect_objects.py"]
|
||||
CMD ["python3", "-u", "detect_objects.py"]
|
||||
|
||||
674
LICENSE
674
LICENSE
@@ -1,21 +1,661 @@
|
||||
The MIT License
|
||||
GNU AFFERO GENERAL PUBLIC LICENSE
|
||||
Version 3, 19 November 2007
|
||||
|
||||
Copyright (c) 2020 Blake Blackshear
|
||||
Copyright (C) 2007 Free Software Foundation, Inc. <https://fsf.org/>
|
||||
Everyone is permitted to copy and distribute verbatim copies
|
||||
of this license document, but changing it is not allowed.
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
Preamble
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
The GNU Affero General Public License is a free, copyleft license for
|
||||
software and other kinds of works, specifically designed to ensure
|
||||
cooperation with the community in the case of network server software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
The licenses for most software and other practical works are designed
|
||||
to take away your freedom to share and change the works. By contrast,
|
||||
our General Public Licenses are intended to guarantee your freedom to
|
||||
share and change all versions of a program--to make sure it remains free
|
||||
software for all its users.
|
||||
|
||||
When we speak of free software, we are referring to freedom, not
|
||||
price. Our General Public Licenses are designed to make sure that you
|
||||
have the freedom to distribute copies of free software (and charge for
|
||||
them if you wish), that you receive source code or can get it if you
|
||||
want it, that you can change the software or use pieces of it in new
|
||||
free programs, and that you know you can do these things.
|
||||
|
||||
Developers that use our General Public Licenses protect your rights
|
||||
with two steps: (1) assert copyright on the software, and (2) offer
|
||||
you this License which gives you legal permission to copy, distribute
|
||||
and/or modify the software.
|
||||
|
||||
A secondary benefit of defending all users' freedom is that
|
||||
improvements made in alternate versions of the program, if they
|
||||
receive widespread use, become available for other developers to
|
||||
incorporate. Many developers of free software are heartened and
|
||||
encouraged by the resulting cooperation. However, in the case of
|
||||
software used on network servers, this result may fail to come about.
|
||||
The GNU General Public License permits making a modified version and
|
||||
letting the public access it on a server without ever releasing its
|
||||
source code to the public.
|
||||
|
||||
The GNU Affero General Public License is designed specifically to
|
||||
ensure that, in such cases, the modified source code becomes available
|
||||
to the community. It requires the operator of a network server to
|
||||
provide the source code of the modified version running there to the
|
||||
users of that server. Therefore, public use of a modified version, on
|
||||
a publicly accessible server, gives the public access to the source
|
||||
code of the modified version.
|
||||
|
||||
An older license, called the Affero General Public License and
|
||||
published by Affero, was designed to accomplish similar goals. This is
|
||||
a different license, not a version of the Affero GPL, but Affero has
|
||||
released a new version of the Affero GPL which permits relicensing under
|
||||
this license.
|
||||
|
||||
The precise terms and conditions for copying, distribution and
|
||||
modification follow.
|
||||
|
||||
TERMS AND CONDITIONS
|
||||
|
||||
0. Definitions.
|
||||
|
||||
"This License" refers to version 3 of the GNU Affero General Public License.
|
||||
|
||||
"Copyright" also means copyright-like laws that apply to other kinds of
|
||||
works, such as semiconductor masks.
|
||||
|
||||
"The Program" refers to any copyrightable work licensed under this
|
||||
License. Each licensee is addressed as "you". "Licensees" and
|
||||
"recipients" may be individuals or organizations.
|
||||
|
||||
To "modify" a work means to copy from or adapt all or part of the work
|
||||
in a fashion requiring copyright permission, other than the making of an
|
||||
exact copy. The resulting work is called a "modified version" of the
|
||||
earlier work or a work "based on" the earlier work.
|
||||
|
||||
A "covered work" means either the unmodified Program or a work based
|
||||
on the Program.
|
||||
|
||||
To "propagate" a work means to do anything with it that, without
|
||||
permission, would make you directly or secondarily liable for
|
||||
infringement under applicable copyright law, except executing it on a
|
||||
computer or modifying a private copy. Propagation includes copying,
|
||||
distribution (with or without modification), making available to the
|
||||
public, and in some countries other activities as well.
|
||||
|
||||
To "convey" a work means any kind of propagation that enables other
|
||||
parties to make or receive copies. Mere interaction with a user through
|
||||
a computer network, with no transfer of a copy, is not conveying.
|
||||
|
||||
An interactive user interface displays "Appropriate Legal Notices"
|
||||
to the extent that it includes a convenient and prominently visible
|
||||
feature that (1) displays an appropriate copyright notice, and (2)
|
||||
tells the user that there is no warranty for the work (except to the
|
||||
extent that warranties are provided), that licensees may convey the
|
||||
work under this License, and how to view a copy of this License. If
|
||||
the interface presents a list of user commands or options, such as a
|
||||
menu, a prominent item in the list meets this criterion.
|
||||
|
||||
1. Source Code.
|
||||
|
||||
The "source code" for a work means the preferred form of the work
|
||||
for making modifications to it. "Object code" means any non-source
|
||||
form of a work.
|
||||
|
||||
A "Standard Interface" means an interface that either is an official
|
||||
standard defined by a recognized standards body, or, in the case of
|
||||
interfaces specified for a particular programming language, one that
|
||||
is widely used among developers working in that language.
|
||||
|
||||
The "System Libraries" of an executable work include anything, other
|
||||
than the work as a whole, that (a) is included in the normal form of
|
||||
packaging a Major Component, but which is not part of that Major
|
||||
Component, and (b) serves only to enable use of the work with that
|
||||
Major Component, or to implement a Standard Interface for which an
|
||||
implementation is available to the public in source code form. A
|
||||
"Major Component", in this context, means a major essential component
|
||||
(kernel, window system, and so on) of the specific operating system
|
||||
(if any) on which the executable work runs, or a compiler used to
|
||||
produce the work, or an object code interpreter used to run it.
|
||||
|
||||
The "Corresponding Source" for a work in object code form means all
|
||||
the source code needed to generate, install, and (for an executable
|
||||
work) run the object code and to modify the work, including scripts to
|
||||
control those activities. However, it does not include the work's
|
||||
System Libraries, or general-purpose tools or generally available free
|
||||
programs which are used unmodified in performing those activities but
|
||||
which are not part of the work. For example, Corresponding Source
|
||||
includes interface definition files associated with source files for
|
||||
the work, and the source code for shared libraries and dynamically
|
||||
linked subprograms that the work is specifically designed to require,
|
||||
such as by intimate data communication or control flow between those
|
||||
subprograms and other parts of the work.
|
||||
|
||||
The Corresponding Source need not include anything that users
|
||||
can regenerate automatically from other parts of the Corresponding
|
||||
Source.
|
||||
|
||||
The Corresponding Source for a work in source code form is that
|
||||
same work.
|
||||
|
||||
2. Basic Permissions.
|
||||
|
||||
All rights granted under this License are granted for the term of
|
||||
copyright on the Program, and are irrevocable provided the stated
|
||||
conditions are met. This License explicitly affirms your unlimited
|
||||
permission to run the unmodified Program. The output from running a
|
||||
covered work is covered by this License only if the output, given its
|
||||
content, constitutes a covered work. This License acknowledges your
|
||||
rights of fair use or other equivalent, as provided by copyright law.
|
||||
|
||||
You may make, run and propagate covered works that you do not
|
||||
convey, without conditions so long as your license otherwise remains
|
||||
in force. You may convey covered works to others for the sole purpose
|
||||
of having them make modifications exclusively for you, or provide you
|
||||
with facilities for running those works, provided that you comply with
|
||||
the terms of this License in conveying all material for which you do
|
||||
not control copyright. Those thus making or running the covered works
|
||||
for you must do so exclusively on your behalf, under your direction
|
||||
and control, on terms that prohibit them from making any copies of
|
||||
your copyrighted material outside their relationship with you.
|
||||
|
||||
Conveying under any other circumstances is permitted solely under
|
||||
the conditions stated below. Sublicensing is not allowed; section 10
|
||||
makes it unnecessary.
|
||||
|
||||
3. Protecting Users' Legal Rights From Anti-Circumvention Law.
|
||||
|
||||
No covered work shall be deemed part of an effective technological
|
||||
measure under any applicable law fulfilling obligations under article
|
||||
11 of the WIPO copyright treaty adopted on 20 December 1996, or
|
||||
similar laws prohibiting or restricting circumvention of such
|
||||
measures.
|
||||
|
||||
When you convey a covered work, you waive any legal power to forbid
|
||||
circumvention of technological measures to the extent such circumvention
|
||||
is effected by exercising rights under this License with respect to
|
||||
the covered work, and you disclaim any intention to limit operation or
|
||||
modification of the work as a means of enforcing, against the work's
|
||||
users, your or third parties' legal rights to forbid circumvention of
|
||||
technological measures.
|
||||
|
||||
4. Conveying Verbatim Copies.
|
||||
|
||||
You may convey verbatim copies of the Program's source code as you
|
||||
receive it, in any medium, provided that you conspicuously and
|
||||
appropriately publish on each copy an appropriate copyright notice;
|
||||
keep intact all notices stating that this License and any
|
||||
non-permissive terms added in accord with section 7 apply to the code;
|
||||
keep intact all notices of the absence of any warranty; and give all
|
||||
recipients a copy of this License along with the Program.
|
||||
|
||||
You may charge any price or no price for each copy that you convey,
|
||||
and you may offer support or warranty protection for a fee.
|
||||
|
||||
5. Conveying Modified Source Versions.
|
||||
|
||||
You may convey a work based on the Program, or the modifications to
|
||||
produce it from the Program, in the form of source code under the
|
||||
terms of section 4, provided that you also meet all of these conditions:
|
||||
|
||||
a) The work must carry prominent notices stating that you modified
|
||||
it, and giving a relevant date.
|
||||
|
||||
b) The work must carry prominent notices stating that it is
|
||||
released under this License and any conditions added under section
|
||||
7. This requirement modifies the requirement in section 4 to
|
||||
"keep intact all notices".
|
||||
|
||||
c) You must license the entire work, as a whole, under this
|
||||
License to anyone who comes into possession of a copy. This
|
||||
License will therefore apply, along with any applicable section 7
|
||||
additional terms, to the whole of the work, and all its parts,
|
||||
regardless of how they are packaged. This License gives no
|
||||
permission to license the work in any other way, but it does not
|
||||
invalidate such permission if you have separately received it.
|
||||
|
||||
d) If the work has interactive user interfaces, each must display
|
||||
Appropriate Legal Notices; however, if the Program has interactive
|
||||
interfaces that do not display Appropriate Legal Notices, your
|
||||
work need not make them do so.
|
||||
|
||||
A compilation of a covered work with other separate and independent
|
||||
works, which are not by their nature extensions of the covered work,
|
||||
and which are not combined with it such as to form a larger program,
|
||||
in or on a volume of a storage or distribution medium, is called an
|
||||
"aggregate" if the compilation and its resulting copyright are not
|
||||
used to limit the access or legal rights of the compilation's users
|
||||
beyond what the individual works permit. Inclusion of a covered work
|
||||
in an aggregate does not cause this License to apply to the other
|
||||
parts of the aggregate.
|
||||
|
||||
6. Conveying Non-Source Forms.
|
||||
|
||||
You may convey a covered work in object code form under the terms
|
||||
of sections 4 and 5, provided that you also convey the
|
||||
machine-readable Corresponding Source under the terms of this License,
|
||||
in one of these ways:
|
||||
|
||||
a) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by the
|
||||
Corresponding Source fixed on a durable physical medium
|
||||
customarily used for software interchange.
|
||||
|
||||
b) Convey the object code in, or embodied in, a physical product
|
||||
(including a physical distribution medium), accompanied by a
|
||||
written offer, valid for at least three years and valid for as
|
||||
long as you offer spare parts or customer support for that product
|
||||
model, to give anyone who possesses the object code either (1) a
|
||||
copy of the Corresponding Source for all the software in the
|
||||
product that is covered by this License, on a durable physical
|
||||
medium customarily used for software interchange, for a price no
|
||||
more than your reasonable cost of physically performing this
|
||||
conveying of source, or (2) access to copy the
|
||||
Corresponding Source from a network server at no charge.
|
||||
|
||||
c) Convey individual copies of the object code with a copy of the
|
||||
written offer to provide the Corresponding Source. This
|
||||
alternative is allowed only occasionally and noncommercially, and
|
||||
only if you received the object code with such an offer, in accord
|
||||
with subsection 6b.
|
||||
|
||||
d) Convey the object code by offering access from a designated
|
||||
place (gratis or for a charge), and offer equivalent access to the
|
||||
Corresponding Source in the same way through the same place at no
|
||||
further charge. You need not require recipients to copy the
|
||||
Corresponding Source along with the object code. If the place to
|
||||
copy the object code is a network server, the Corresponding Source
|
||||
may be on a different server (operated by you or a third party)
|
||||
that supports equivalent copying facilities, provided you maintain
|
||||
clear directions next to the object code saying where to find the
|
||||
Corresponding Source. Regardless of what server hosts the
|
||||
Corresponding Source, you remain obligated to ensure that it is
|
||||
available for as long as needed to satisfy these requirements.
|
||||
|
||||
e) Convey the object code using peer-to-peer transmission, provided
|
||||
you inform other peers where the object code and Corresponding
|
||||
Source of the work are being offered to the general public at no
|
||||
charge under subsection 6d.
|
||||
|
||||
A separable portion of the object code, whose source code is excluded
|
||||
from the Corresponding Source as a System Library, need not be
|
||||
included in conveying the object code work.
|
||||
|
||||
A "User Product" is either (1) a "consumer product", which means any
|
||||
tangible personal property which is normally used for personal, family,
|
||||
or household purposes, or (2) anything designed or sold for incorporation
|
||||
into a dwelling. In determining whether a product is a consumer product,
|
||||
doubtful cases shall be resolved in favor of coverage. For a particular
|
||||
product received by a particular user, "normally used" refers to a
|
||||
typical or common use of that class of product, regardless of the status
|
||||
of the particular user or of the way in which the particular user
|
||||
actually uses, or expects or is expected to use, the product. A product
|
||||
is a consumer product regardless of whether the product has substantial
|
||||
commercial, industrial or non-consumer uses, unless such uses represent
|
||||
the only significant mode of use of the product.
|
||||
|
||||
"Installation Information" for a User Product means any methods,
|
||||
procedures, authorization keys, or other information required to install
|
||||
and execute modified versions of a covered work in that User Product from
|
||||
a modified version of its Corresponding Source. The information must
|
||||
suffice to ensure that the continued functioning of the modified object
|
||||
code is in no case prevented or interfered with solely because
|
||||
modification has been made.
|
||||
|
||||
If you convey an object code work under this section in, or with, or
|
||||
specifically for use in, a User Product, and the conveying occurs as
|
||||
part of a transaction in which the right of possession and use of the
|
||||
User Product is transferred to the recipient in perpetuity or for a
|
||||
fixed term (regardless of how the transaction is characterized), the
|
||||
Corresponding Source conveyed under this section must be accompanied
|
||||
by the Installation Information. But this requirement does not apply
|
||||
if neither you nor any third party retains the ability to install
|
||||
modified object code on the User Product (for example, the work has
|
||||
been installed in ROM).
|
||||
|
||||
The requirement to provide Installation Information does not include a
|
||||
requirement to continue to provide support service, warranty, or updates
|
||||
for a work that has been modified or installed by the recipient, or for
|
||||
the User Product in which it has been modified or installed. Access to a
|
||||
network may be denied when the modification itself materially and
|
||||
adversely affects the operation of the network or violates the rules and
|
||||
protocols for communication across the network.
|
||||
|
||||
Corresponding Source conveyed, and Installation Information provided,
|
||||
in accord with this section must be in a format that is publicly
|
||||
documented (and with an implementation available to the public in
|
||||
source code form), and must require no special password or key for
|
||||
unpacking, reading or copying.
|
||||
|
||||
7. Additional Terms.
|
||||
|
||||
"Additional permissions" are terms that supplement the terms of this
|
||||
License by making exceptions from one or more of its conditions.
|
||||
Additional permissions that are applicable to the entire Program shall
|
||||
be treated as though they were included in this License, to the extent
|
||||
that they are valid under applicable law. If additional permissions
|
||||
apply only to part of the Program, that part may be used separately
|
||||
under those permissions, but the entire Program remains governed by
|
||||
this License without regard to the additional permissions.
|
||||
|
||||
When you convey a copy of a covered work, you may at your option
|
||||
remove any additional permissions from that copy, or from any part of
|
||||
it. (Additional permissions may be written to require their own
|
||||
removal in certain cases when you modify the work.) You may place
|
||||
additional permissions on material, added by you to a covered work,
|
||||
for which you have or can give appropriate copyright permission.
|
||||
|
||||
Notwithstanding any other provision of this License, for material you
|
||||
add to a covered work, you may (if authorized by the copyright holders of
|
||||
that material) supplement the terms of this License with terms:
|
||||
|
||||
a) Disclaiming warranty or limiting liability differently from the
|
||||
terms of sections 15 and 16 of this License; or
|
||||
|
||||
b) Requiring preservation of specified reasonable legal notices or
|
||||
author attributions in that material or in the Appropriate Legal
|
||||
Notices displayed by works containing it; or
|
||||
|
||||
c) Prohibiting misrepresentation of the origin of that material, or
|
||||
requiring that modified versions of such material be marked in
|
||||
reasonable ways as different from the original version; or
|
||||
|
||||
d) Limiting the use for publicity purposes of names of licensors or
|
||||
authors of the material; or
|
||||
|
||||
e) Declining to grant rights under trademark law for use of some
|
||||
trade names, trademarks, or service marks; or
|
||||
|
||||
f) Requiring indemnification of licensors and authors of that
|
||||
material by anyone who conveys the material (or modified versions of
|
||||
it) with contractual assumptions of liability to the recipient, for
|
||||
any liability that these contractual assumptions directly impose on
|
||||
those licensors and authors.
|
||||
|
||||
All other non-permissive additional terms are considered "further
|
||||
restrictions" within the meaning of section 10. If the Program as you
|
||||
received it, or any part of it, contains a notice stating that it is
|
||||
governed by this License along with a term that is a further
|
||||
restriction, you may remove that term. If a license document contains
|
||||
a further restriction but permits relicensing or conveying under this
|
||||
License, you may add to a covered work material governed by the terms
|
||||
of that license document, provided that the further restriction does
|
||||
not survive such relicensing or conveying.
|
||||
|
||||
If you add terms to a covered work in accord with this section, you
|
||||
must place, in the relevant source files, a statement of the
|
||||
additional terms that apply to those files, or a notice indicating
|
||||
where to find the applicable terms.
|
||||
|
||||
Additional terms, permissive or non-permissive, may be stated in the
|
||||
form of a separately written license, or stated as exceptions;
|
||||
the above requirements apply either way.
|
||||
|
||||
8. Termination.
|
||||
|
||||
You may not propagate or modify a covered work except as expressly
|
||||
provided under this License. Any attempt otherwise to propagate or
|
||||
modify it is void, and will automatically terminate your rights under
|
||||
this License (including any patent licenses granted under the third
|
||||
paragraph of section 11).
|
||||
|
||||
However, if you cease all violation of this License, then your
|
||||
license from a particular copyright holder is reinstated (a)
|
||||
provisionally, unless and until the copyright holder explicitly and
|
||||
finally terminates your license, and (b) permanently, if the copyright
|
||||
holder fails to notify you of the violation by some reasonable means
|
||||
prior to 60 days after the cessation.
|
||||
|
||||
Moreover, your license from a particular copyright holder is
|
||||
reinstated permanently if the copyright holder notifies you of the
|
||||
violation by some reasonable means, this is the first time you have
|
||||
received notice of violation of this License (for any work) from that
|
||||
copyright holder, and you cure the violation prior to 30 days after
|
||||
your receipt of the notice.
|
||||
|
||||
Termination of your rights under this section does not terminate the
|
||||
licenses of parties who have received copies or rights from you under
|
||||
this License. If your rights have been terminated and not permanently
|
||||
reinstated, you do not qualify to receive new licenses for the same
|
||||
material under section 10.
|
||||
|
||||
9. Acceptance Not Required for Having Copies.
|
||||
|
||||
You are not required to accept this License in order to receive or
|
||||
run a copy of the Program. Ancillary propagation of a covered work
|
||||
occurring solely as a consequence of using peer-to-peer transmission
|
||||
to receive a copy likewise does not require acceptance. However,
|
||||
nothing other than this License grants you permission to propagate or
|
||||
modify any covered work. These actions infringe copyright if you do
|
||||
not accept this License. Therefore, by modifying or propagating a
|
||||
covered work, you indicate your acceptance of this License to do so.
|
||||
|
||||
10. Automatic Licensing of Downstream Recipients.
|
||||
|
||||
Each time you convey a covered work, the recipient automatically
|
||||
receives a license from the original licensors, to run, modify and
|
||||
propagate that work, subject to this License. You are not responsible
|
||||
for enforcing compliance by third parties with this License.
|
||||
|
||||
An "entity transaction" is a transaction transferring control of an
|
||||
organization, or substantially all assets of one, or subdividing an
|
||||
organization, or merging organizations. If propagation of a covered
|
||||
work results from an entity transaction, each party to that
|
||||
transaction who receives a copy of the work also receives whatever
|
||||
licenses to the work the party's predecessor in interest had or could
|
||||
give under the previous paragraph, plus a right to possession of the
|
||||
Corresponding Source of the work from the predecessor in interest, if
|
||||
the predecessor has it or can get it with reasonable efforts.
|
||||
|
||||
You may not impose any further restrictions on the exercise of the
|
||||
rights granted or affirmed under this License. For example, you may
|
||||
not impose a license fee, royalty, or other charge for exercise of
|
||||
rights granted under this License, and you may not initiate litigation
|
||||
(including a cross-claim or counterclaim in a lawsuit) alleging that
|
||||
any patent claim is infringed by making, using, selling, offering for
|
||||
sale, or importing the Program or any portion of it.
|
||||
|
||||
11. Patents.
|
||||
|
||||
A "contributor" is a copyright holder who authorizes use under this
|
||||
License of the Program or a work on which the Program is based. The
|
||||
work thus licensed is called the contributor's "contributor version".
|
||||
|
||||
A contributor's "essential patent claims" are all patent claims
|
||||
owned or controlled by the contributor, whether already acquired or
|
||||
hereafter acquired, that would be infringed by some manner, permitted
|
||||
by this License, of making, using, or selling its contributor version,
|
||||
but do not include claims that would be infringed only as a
|
||||
consequence of further modification of the contributor version. For
|
||||
purposes of this definition, "control" includes the right to grant
|
||||
patent sublicenses in a manner consistent with the requirements of
|
||||
this License.
|
||||
|
||||
Each contributor grants you a non-exclusive, worldwide, royalty-free
|
||||
patent license under the contributor's essential patent claims, to
|
||||
make, use, sell, offer for sale, import and otherwise run, modify and
|
||||
propagate the contents of its contributor version.
|
||||
|
||||
In the following three paragraphs, a "patent license" is any express
|
||||
agreement or commitment, however denominated, not to enforce a patent
|
||||
(such as an express permission to practice a patent or covenant not to
|
||||
sue for patent infringement). To "grant" such a patent license to a
|
||||
party means to make such an agreement or commitment not to enforce a
|
||||
patent against the party.
|
||||
|
||||
If you convey a covered work, knowingly relying on a patent license,
|
||||
and the Corresponding Source of the work is not available for anyone
|
||||
to copy, free of charge and under the terms of this License, through a
|
||||
publicly available network server or other readily accessible means,
|
||||
then you must either (1) cause the Corresponding Source to be so
|
||||
available, or (2) arrange to deprive yourself of the benefit of the
|
||||
patent license for this particular work, or (3) arrange, in a manner
|
||||
consistent with the requirements of this License, to extend the patent
|
||||
license to downstream recipients. "Knowingly relying" means you have
|
||||
actual knowledge that, but for the patent license, your conveying the
|
||||
covered work in a country, or your recipient's use of the covered work
|
||||
in a country, would infringe one or more identifiable patents in that
|
||||
country that you have reason to believe are valid.
|
||||
|
||||
If, pursuant to or in connection with a single transaction or
|
||||
arrangement, you convey, or propagate by procuring conveyance of, a
|
||||
covered work, and grant a patent license to some of the parties
|
||||
receiving the covered work authorizing them to use, propagate, modify
|
||||
or convey a specific copy of the covered work, then the patent license
|
||||
you grant is automatically extended to all recipients of the covered
|
||||
work and works based on it.
|
||||
|
||||
A patent license is "discriminatory" if it does not include within
|
||||
the scope of its coverage, prohibits the exercise of, or is
|
||||
conditioned on the non-exercise of one or more of the rights that are
|
||||
specifically granted under this License. You may not convey a covered
|
||||
work if you are a party to an arrangement with a third party that is
|
||||
in the business of distributing software, under which you make payment
|
||||
to the third party based on the extent of your activity of conveying
|
||||
the work, and under which the third party grants, to any of the
|
||||
parties who would receive the covered work from you, a discriminatory
|
||||
patent license (a) in connection with copies of the covered work
|
||||
conveyed by you (or copies made from those copies), or (b) primarily
|
||||
for and in connection with specific products or compilations that
|
||||
contain the covered work, unless you entered into that arrangement,
|
||||
or that patent license was granted, prior to 28 March 2007.
|
||||
|
||||
Nothing in this License shall be construed as excluding or limiting
|
||||
any implied license or other defenses to infringement that may
|
||||
otherwise be available to you under applicable patent law.
|
||||
|
||||
12. No Surrender of Others' Freedom.
|
||||
|
||||
If conditions are imposed on you (whether by court order, agreement or
|
||||
otherwise) that contradict the conditions of this License, they do not
|
||||
excuse you from the conditions of this License. If you cannot convey a
|
||||
covered work so as to satisfy simultaneously your obligations under this
|
||||
License and any other pertinent obligations, then as a consequence you may
|
||||
not convey it at all. For example, if you agree to terms that obligate you
|
||||
to collect a royalty for further conveying from those to whom you convey
|
||||
the Program, the only way you could satisfy both those terms and this
|
||||
License would be to refrain entirely from conveying the Program.
|
||||
|
||||
13. Remote Network Interaction; Use with the GNU General Public License.
|
||||
|
||||
Notwithstanding any other provision of this License, if you modify the
|
||||
Program, your modified version must prominently offer all users
|
||||
interacting with it remotely through a computer network (if your version
|
||||
supports such interaction) an opportunity to receive the Corresponding
|
||||
Source of your version by providing access to the Corresponding Source
|
||||
from a network server at no charge, through some standard or customary
|
||||
means of facilitating copying of software. This Corresponding Source
|
||||
shall include the Corresponding Source for any work covered by version 3
|
||||
of the GNU General Public License that is incorporated pursuant to the
|
||||
following paragraph.
|
||||
|
||||
Notwithstanding any other provision of this License, you have
|
||||
permission to link or combine any covered work with a work licensed
|
||||
under version 3 of the GNU General Public License into a single
|
||||
combined work, and to convey the resulting work. The terms of this
|
||||
License will continue to apply to the part which is the covered work,
|
||||
but the work with which it is combined will remain governed by version
|
||||
3 of the GNU General Public License.
|
||||
|
||||
14. Revised Versions of this License.
|
||||
|
||||
The Free Software Foundation may publish revised and/or new versions of
|
||||
the GNU Affero General Public License from time to time. Such new versions
|
||||
will be similar in spirit to the present version, but may differ in detail to
|
||||
address new problems or concerns.
|
||||
|
||||
Each version is given a distinguishing version number. If the
|
||||
Program specifies that a certain numbered version of the GNU Affero General
|
||||
Public License "or any later version" applies to it, you have the
|
||||
option of following the terms and conditions either of that numbered
|
||||
version or of any later version published by the Free Software
|
||||
Foundation. If the Program does not specify a version number of the
|
||||
GNU Affero General Public License, you may choose any version ever published
|
||||
by the Free Software Foundation.
|
||||
|
||||
If the Program specifies that a proxy can decide which future
|
||||
versions of the GNU Affero General Public License can be used, that proxy's
|
||||
public statement of acceptance of a version permanently authorizes you
|
||||
to choose that version for the Program.
|
||||
|
||||
Later license versions may give you additional or different
|
||||
permissions. However, no additional obligations are imposed on any
|
||||
author or copyright holder as a result of your choosing to follow a
|
||||
later version.
|
||||
|
||||
15. Disclaimer of Warranty.
|
||||
|
||||
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY
|
||||
APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT
|
||||
HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY
|
||||
OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO,
|
||||
THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR
|
||||
PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM
|
||||
IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF
|
||||
ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
|
||||
|
||||
16. Limitation of Liability.
|
||||
|
||||
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
|
||||
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS
|
||||
THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY
|
||||
GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE
|
||||
USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF
|
||||
DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD
|
||||
PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS),
|
||||
EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF
|
||||
SUCH DAMAGES.
|
||||
|
||||
17. Interpretation of Sections 15 and 16.
|
||||
|
||||
If the disclaimer of warranty and limitation of liability provided
|
||||
above cannot be given local legal effect according to their terms,
|
||||
reviewing courts shall apply local law that most closely approximates
|
||||
an absolute waiver of all civil liability in connection with the
|
||||
Program, unless a warranty or assumption of liability accompanies a
|
||||
copy of the Program in return for a fee.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
How to Apply These Terms to Your New Programs
|
||||
|
||||
If you develop a new program, and you want it to be of the greatest
|
||||
possible use to the public, the best way to achieve this is to make it
|
||||
free software which everyone can redistribute and change under these terms.
|
||||
|
||||
To do so, attach the following notices to the program. It is safest
|
||||
to attach them to the start of each source file to most effectively
|
||||
state the exclusion of warranty; and each file should have at least
|
||||
the "copyright" line and a pointer to where the full notice is found.
|
||||
|
||||
<one line to give the program's name and a brief idea of what it does.>
|
||||
Copyright (C) <year> <name of author>
|
||||
|
||||
This program is free software: you can redistribute it and/or modify
|
||||
it under the terms of the GNU Affero General Public License as published
|
||||
by the Free Software Foundation, either version 3 of the License, or
|
||||
(at your option) any later version.
|
||||
|
||||
This program is distributed in the hope that it will be useful,
|
||||
but WITHOUT ANY WARRANTY; without even the implied warranty of
|
||||
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
|
||||
GNU Affero General Public License for more details.
|
||||
|
||||
You should have received a copy of the GNU Affero General Public License
|
||||
along with this program. If not, see <https://www.gnu.org/licenses/>.
|
||||
|
||||
Also add information on how to contact you by electronic and paper mail.
|
||||
|
||||
If your software can interact with users remotely through a computer
|
||||
network, you should also make sure that it provides a way for users to
|
||||
get its source. For example, if your program is a web application, its
|
||||
interface could display a "Source" link that leads users to an archive
|
||||
of the code. There are many ways you could offer source, and different
|
||||
solutions will be better for different programs; see section 13 for the
|
||||
specific requirements.
|
||||
|
||||
You should also get your employer (if you work as a programmer) or school,
|
||||
if any, to sign a "copyright disclaimer" for the program, if necessary.
|
||||
For more information on this, and how to apply and follow the GNU AGPL, see
|
||||
<https://www.gnu.org/licenses/>.
|
||||
|
||||
277
README.md
277
README.md
@@ -1,13 +1,14 @@
|
||||
# Frigate - Realtime Object Detection for IP Cameras
|
||||
Uses OpenCV and Tensorflow to perform realtime object detection locally for IP cameras. Designed for integration with HomeAssistant or others via MQTT.
|
||||
# Frigate - Realtime Object Detection for RTSP Cameras
|
||||
**Note:** This version requires the use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/)
|
||||
|
||||
Use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/) is optional, but highly recommended. On my Intel i7 processor, I can process 2-3 FPS with the CPU. The Coral can process 100+ FPS with very low CPU load.
|
||||
Uses OpenCV and Tensorflow to perform realtime object detection locally for RTSP cameras. Designed for integration with HomeAssistant or others via MQTT.
|
||||
|
||||
- Leverages multiprocessing heavily with an emphasis on realtime over processing every frame
|
||||
- Uses a very low overhead motion detection to determine where to run object detection
|
||||
- Object detection with Tensorflow runs in a separate process
|
||||
- Leverages multiprocessing and threads heavily with an emphasis on realtime over processing every frame
|
||||
- Allows you to define specific regions (squares) in the image to look for objects
|
||||
- No motion detection (for now)
|
||||
- Object detection with Tensorflow runs in a separate thread
|
||||
- Object info is published over MQTT for integration into HomeAssistant as a binary sensor
|
||||
- An endpoint is available to view an MJPEG stream for debugging, but should not be used continuously
|
||||
- An endpoint is available to view an MJPEG stream for debugging
|
||||
|
||||

|
||||
|
||||
@@ -16,250 +17,82 @@ You see multiple bounding boxes because it draws bounding boxes from all frames
|
||||
[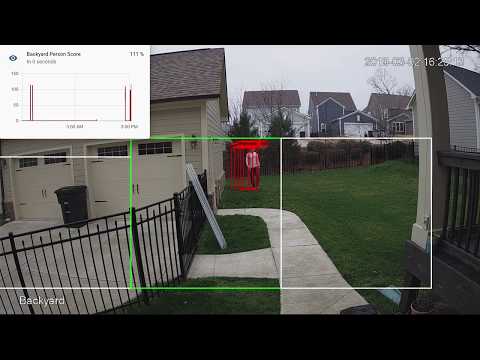](http://www.youtube.com/watch?v=nqHbCtyo4dY "Frigate")
|
||||
|
||||
## Getting Started
|
||||
Build the container with
|
||||
```
|
||||
docker build -t frigate .
|
||||
```
|
||||
|
||||
The `mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite` model is included and used by default. You can use your own model and labels by mounting files in the container at `/frozen_inference_graph.pb` and `/label_map.pbtext`. Models must be compatible with the Coral according to [this](https://coral.withgoogle.com/models/).
|
||||
|
||||
Run the container with
|
||||
```bash
|
||||
```
|
||||
docker run --rm \
|
||||
-name frigate \
|
||||
--privileged \
|
||||
--shm-size=512m \ # should work for a 2-3 cameras
|
||||
-v /dev/bus/usb:/dev/bus/usb \
|
||||
-v <path_to_config_dir>:/config:ro \
|
||||
-v /etc/localtime:/etc/localtime:ro \
|
||||
-p 5000:5000 \
|
||||
-e FRIGATE_RTSP_PASSWORD='password' \
|
||||
blakeblackshear/frigate:stable
|
||||
-e RTSP_PASSWORD='password' \
|
||||
frigate:latest
|
||||
```
|
||||
|
||||
Example docker-compose:
|
||||
```yaml
|
||||
```
|
||||
frigate:
|
||||
container_name: frigate
|
||||
restart: unless-stopped
|
||||
privileged: true
|
||||
shm_size: '1g' # should work for 5-7 cameras
|
||||
image: blakeblackshear/frigate:stable
|
||||
image: frigate:latest
|
||||
volumes:
|
||||
- /dev/bus/usb:/dev/bus/usb
|
||||
- /etc/localtime:/etc/localtime:ro
|
||||
- <path_to_config>:/config
|
||||
- <path_to_directory_for_clips>:/clips
|
||||
ports:
|
||||
- "5000:5000"
|
||||
environment:
|
||||
FRIGATE_RTSP_PASSWORD: "password"
|
||||
RTSP_PASSWORD: "password"
|
||||
```
|
||||
|
||||
A `config.yml` file must exist in the `config` directory. See example [here](config/config.example.yml) and device specific info can be found [here](docs/DEVICES.md).
|
||||
A `config.yml` file must exist in the `config` directory. See example [here](config/config.yml).
|
||||
|
||||
## Recommended Hardware
|
||||
|Name|Inference Speed|Notes|
|
||||
|----|---------------|-----|
|
||||
|Atomic Pi|16ms|Best option for a dedicated low power board with a small number of cameras.|
|
||||
|Intel NUC NUC7i3BNK|8-10ms|Best possible performance. Can handle 7+ cameras at 5fps depending on typical amounts of motion.|
|
||||
|BMAX B2 Plus|10-12ms|Good balance of performance and cost. Also capable of running many other services at the same time as frigate.
|
||||
|
||||
ARM boards are not officially supported at the moment due to some python dependencies that require modification to work on ARM devices. The Raspberry Pi4 gets about 16ms inference speeds, but the hardware acceleration for ffmpeg does not work for converting yuv420 to rgb24. The Atomic Pi is x86 and much more efficient.
|
||||
|
||||
Users have reported varying success in getting frigate to run in a VM. In some cases, the virtualization layer introduces a significant delay in communication with the Coral. If running virtualized in Proxmox, pass the USB card/interface to the virtual machine not the USB ID for faster inference speed.
|
||||
Access the mjpeg stream at `http://localhost:5000/<camera_name>` and the best person snapshot at `http://localhost:5000/<camera_name>/best_person.jpg`
|
||||
|
||||
## Integration with HomeAssistant
|
||||
|
||||
Setup a the camera, binary_sensor, sensor and optionally automation as shown for each camera you define in frigate. Replace <camera_name> with the camera name as defined in the frigate `config.yml` (The `frigate_coral_fps` and `frigate_coral_inference` sensors only need to be defined once)
|
||||
|
||||
```
|
||||
camera:
|
||||
- name: <camera_name> Last Person
|
||||
platform: mqtt
|
||||
topic: frigate/<camera_name>/person/snapshot
|
||||
- name: <camera_name> Last Car
|
||||
platform: mqtt
|
||||
topic: frigate/<camera_name>/car/snapshot
|
||||
|
||||
binary_sensor:
|
||||
- name: <camera_name> Person
|
||||
platform: mqtt
|
||||
state_topic: "frigate/<camera_name>/person"
|
||||
device_class: motion
|
||||
availability_topic: "frigate/available"
|
||||
- name: Camera Last Person
|
||||
platform: generic
|
||||
still_image_url: http://<ip>:5000/<camera_name>/best_person.jpg
|
||||
|
||||
sensor:
|
||||
- platform: rest
|
||||
name: Frigate Debug
|
||||
resource: http://localhost:5000/debug/stats
|
||||
scan_interval: 5
|
||||
json_attributes:
|
||||
- <camera_name>
|
||||
- coral
|
||||
value_template: 'OK'
|
||||
- platform: template
|
||||
sensors:
|
||||
<camera_name>_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["<camera_name>"]["fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
<camera_name>_skipped_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["<camera_name>"]["skipped_fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
<camera_name>_detection_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["<camera_name>"]["detection_fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
frigate_coral_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
frigate_coral_inference:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["inference_speed"] }}'
|
||||
unit_of_measurement: 'ms'
|
||||
|
||||
automation:
|
||||
- alias: Alert me if a person is detected while armed away
|
||||
trigger:
|
||||
platform: state
|
||||
entity_id: binary_sensor.camera_person
|
||||
from: 'off'
|
||||
to: 'on'
|
||||
condition:
|
||||
- condition: state
|
||||
entity_id: alarm_control_panel.home_alarm
|
||||
state: armed_away
|
||||
action:
|
||||
- service: notify.user_telegram
|
||||
data:
|
||||
message: "A person was detected."
|
||||
data:
|
||||
photo:
|
||||
- url: http://<ip>:5000/<camera_name>/person/best.jpg
|
||||
caption: A person was detected.
|
||||
- name: Camera Person
|
||||
platform: mqtt
|
||||
state_topic: "frigate/<camera_name>/objects"
|
||||
value_template: '{{ value_json.person }}'
|
||||
device_class: moving
|
||||
availability_topic: "frigate/available"
|
||||
```
|
||||
## HTTP Endpoints
|
||||
A web server is available on port 5000 with the following endpoints.
|
||||
|
||||
### `/<camera_name>`
|
||||
An mjpeg stream for debugging. Keep in mind the mjpeg endpoint is for debugging only and will put additional load on the system when in use.
|
||||
|
||||
You can access a higher resolution mjpeg stream by appending `h=height-in-pixels` to the endpoint. For example `http://localhost:5000/back?h=1080`. You can also increase the FPS by appending `fps=frame-rate` to the URL such as `http://localhost:5000/back?fps=10` or both with `?fps=10&h=1000`
|
||||
|
||||
### `/<camera_name>/<object_name>/best.jpg`
|
||||
The best snapshot for any object type. It is a full resolution image by default. You can change the size of the image by appending `h=height-in-pixels` to the endpoint.
|
||||
|
||||
### `/<camera_name>/latest.jpg`
|
||||
The most recent frame that frigate has finished processing. It is a full resolution image by default. You can change the size of the image by appending `h=height-in-pixels` to the endpoint.
|
||||
|
||||
### `/debug/stats`
|
||||
Contains some granular debug info that can be used for sensors in HomeAssistant.
|
||||
|
||||
## MQTT Messages
|
||||
These are the MQTT messages generated by Frigate. The default topic_prefix is `frigate`, but can be changed in the config file.
|
||||
|
||||
### frigate/available
|
||||
Designed to be used as an availability topic with HomeAssistant. Possible message are:
|
||||
"online": published when frigate is running (on startup)
|
||||
"offline": published right before frigate stops
|
||||
|
||||
### frigate/<camera_name>/<object_name>
|
||||
Publishes `ON` or `OFF` and is designed to be used a as a binary sensor in HomeAssistant for whether or not that object type is detected.
|
||||
|
||||
### frigate/<camera_name>/<object_name>/snapshot
|
||||
Publishes a jpeg encoded frame of the detected object type. When the object is no longer detected, the highest confidence image is published or the original image
|
||||
is published again.
|
||||
|
||||
### frigate/<camera_name>/events/start
|
||||
Message published at the start of any tracked object. JSON looks as follows:
|
||||
```json
|
||||
{
|
||||
"label": "person",
|
||||
"score": 0.7890625,
|
||||
"box": [
|
||||
468,
|
||||
446,
|
||||
550,
|
||||
592
|
||||
],
|
||||
"area": 11972,
|
||||
"region": [
|
||||
403,
|
||||
395,
|
||||
613,
|
||||
605
|
||||
],
|
||||
"frame_time": 1594298020.819046,
|
||||
"centroid": [
|
||||
509,
|
||||
519
|
||||
],
|
||||
"id": "1594298020.819046-0",
|
||||
"start_time": 1594298020.819046,
|
||||
"top_score": 0.7890625,
|
||||
"history": [
|
||||
{
|
||||
"score": 0.7890625,
|
||||
"box": [
|
||||
468,
|
||||
446,
|
||||
550,
|
||||
592
|
||||
],
|
||||
"region": [
|
||||
403,
|
||||
395,
|
||||
613,
|
||||
605
|
||||
],
|
||||
"centroid": [
|
||||
509,
|
||||
519
|
||||
],
|
||||
"frame_time": 1594298020.819046
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### frigate/<camera_name>/events/end
|
||||
Same as `frigate/<camera_name>/events/start`, but with an `end_time` property as well.
|
||||
|
||||
### frigate/<zone_name>/<object_name>
|
||||
Publishes `ON` or `OFF` and is designed to be used a as a binary sensor in HomeAssistant for whether or not that object type is detected in the zone.
|
||||
|
||||
## Using a custom model or labels
|
||||
Models for both CPU and EdgeTPU (Coral) are bundled in the image. You can use your own models with volume mounts:
|
||||
- CPU Model: `/cpu_model.tflite`
|
||||
- EdgeTPU Model: `/edgetpu_model.tflite`
|
||||
- Labels: `/labelmap.txt`
|
||||
|
||||
### Customizing the Labelmap
|
||||
The labelmap can be customized to your needs. A common reason to do this is to combine multiple object types that are easily confused when you don't need to be as granular such as car/truck. You must retain the same number of labels, but you can change the names. To change:
|
||||
|
||||
- Download the [COCO labelmap](https://dl.google.com/coral/canned_models/coco_labels.txt)
|
||||
- Modify the label names as desired. For example, change `7 truck` to `7 car`
|
||||
- Mount the new file at `/labelmap.txt` in the container with an additional volume
|
||||
```
|
||||
-v ./config/labelmap.txt:/labelmap.txt
|
||||
```
|
||||
|
||||
## Masks and limiting detection to a certain area
|
||||
You can create a *bitmap (bmp)* file the same aspect ratio as your camera feed to limit detection to certain areas. The mask works by looking at the bottom center of any bounding box (first image, red dot below) and comparing that to your mask. If that red dot falls on an area of your mask that is black, the detection (and motion) will be ignored. The mask in the second image would limit detection on this camera to only objects that are in the front yard and not the street.
|
||||
|
||||
<img src="docs/example-mask-check-point.png" height="300">
|
||||
<img src="docs/example-mask.bmp" height="300">
|
||||
<img src="docs/example-mask-overlay.png" height="300">
|
||||
|
||||
## Zones
|
||||
Zones allow you to define a specific area of the frame and apply additional filters for object types so you can determine whether or not an object is within a particular area. Zones cannot have the same name as a camera. If desired, a single zone can include multiple cameras if you have multiple cameras covering the same area. See the sample config for details on how to configure.
|
||||
|
||||
During testing, `draw_zones` can be set in the config to tell frigate to draw the zone on the frames so you can adjust as needed. The zone line will increase in thickness when any object enters the zone.
|
||||
|
||||

|
||||
|
||||
## Tips
|
||||
- Lower the framerate of the video feed on the camera to reduce the CPU usage for capturing the feed. Not as effective, but you can also modify the `take_frame` [configuration](config/config.example.yml) for each camera to only analyze every other frame, or every third frame, etc.
|
||||
- Hard code the resolution of each camera in your config if you are having difficulty starting frigate or if the initial ffprobe for camerea resolution fails or returns incorrect info. Example:
|
||||
```
|
||||
cameras:
|
||||
back:
|
||||
ffmpeg:
|
||||
input: rtsp://<camera>
|
||||
height: 1080
|
||||
width: 1920
|
||||
```
|
||||
- Additional logging is available in the docker container - You can view the logs by running `docker logs -t frigate`
|
||||
- Object configuration - Tracked objects types, sizes and thresholds can be defined globally and/or on a per camera basis. The global and camera object configuration is *merged*. For example, if you defined tracking person, car, and truck globally but modified your backyard camera to only track person, the global config would merge making the effective list for the backyard camera still contain person, car and truck. If you want precise object tracking per camera, best practice to put a minimal list of objects at the global level and expand objects on a per camera basis. Object threshold and area configuration will be used first from the camera object config (if defined) and then from the global config. See the [example config](config/config.example.yml) for more information.
|
||||
- Lower the framerate of the RTSP feed on the camera to reduce the CPU usage for capturing the feed
|
||||
|
||||
## Future improvements
|
||||
- [x] Remove motion detection for now
|
||||
- [x] Try running object detection in a thread rather than a process
|
||||
- [x] Implement min person size again
|
||||
- [x] Switch to a config file
|
||||
- [x] Handle multiple cameras in the same container
|
||||
- [ ] Attempt to figure out coral symlinking
|
||||
- [ ] Add object list to config with min scores for mqtt
|
||||
- [ ] Move mjpeg encoding to a separate process
|
||||
- [ ] Simplify motion detection (check entire image against mask, resize instead of gaussian blur)
|
||||
- [ ] See if motion detection is even worth running
|
||||
- [ ] Scan for people across entire image rather than specfic regions
|
||||
- [ ] Dynamically resize detection area and follow people
|
||||
- [ ] Add ability to turn detection on and off via MQTT
|
||||
- [ ] Output movie clips of people for notifications, etc.
|
||||
- [ ] Integrate with homeassistant push camera
|
||||
- [ ] Merge bounding boxes that span multiple regions
|
||||
- [ ] Implement mode to save labeled objects for training
|
||||
- [ ] Try and reduce CPU usage by simplifying the tensorflow model to just include the objects we care about
|
||||
- [ ] Look into GPU accelerated decoding of RTSP stream
|
||||
- [ ] Send video over a socket and use JSMPEG
|
||||
- [x] Look into neural compute stick
|
||||
|
||||
79
benchmark.py
79
benchmark.py
@@ -1,79 +0,0 @@
|
||||
import os
|
||||
from statistics import mean
|
||||
import multiprocessing as mp
|
||||
import numpy as np
|
||||
import datetime
|
||||
from frigate.edgetpu import ObjectDetector, EdgeTPUProcess, RemoteObjectDetector, load_labels
|
||||
|
||||
my_frame = np.expand_dims(np.full((300,300,3), 1, np.uint8), axis=0)
|
||||
labels = load_labels('/labelmap.txt')
|
||||
|
||||
######
|
||||
# Minimal same process runner
|
||||
######
|
||||
# object_detector = ObjectDetector()
|
||||
# tensor_input = np.expand_dims(np.full((300,300,3), 0, np.uint8), axis=0)
|
||||
|
||||
# start = datetime.datetime.now().timestamp()
|
||||
|
||||
# frame_times = []
|
||||
# for x in range(0, 1000):
|
||||
# start_frame = datetime.datetime.now().timestamp()
|
||||
|
||||
# tensor_input[:] = my_frame
|
||||
# detections = object_detector.detect_raw(tensor_input)
|
||||
# parsed_detections = []
|
||||
# for d in detections:
|
||||
# if d[1] < 0.4:
|
||||
# break
|
||||
# parsed_detections.append((
|
||||
# labels[int(d[0])],
|
||||
# float(d[1]),
|
||||
# (d[2], d[3], d[4], d[5])
|
||||
# ))
|
||||
# frame_times.append(datetime.datetime.now().timestamp()-start_frame)
|
||||
|
||||
# duration = datetime.datetime.now().timestamp()-start
|
||||
# print(f"Processed for {duration:.2f} seconds.")
|
||||
# print(f"Average frame processing time: {mean(frame_times)*1000:.2f}ms")
|
||||
|
||||
######
|
||||
# Separate process runner
|
||||
######
|
||||
def start(id, num_detections, detection_queue):
|
||||
object_detector = RemoteObjectDetector(str(id), '/labelmap.txt', detection_queue)
|
||||
start = datetime.datetime.now().timestamp()
|
||||
|
||||
frame_times = []
|
||||
for x in range(0, num_detections):
|
||||
start_frame = datetime.datetime.now().timestamp()
|
||||
detections = object_detector.detect(my_frame)
|
||||
frame_times.append(datetime.datetime.now().timestamp()-start_frame)
|
||||
|
||||
duration = datetime.datetime.now().timestamp()-start
|
||||
print(f"{id} - Processed for {duration:.2f} seconds.")
|
||||
print(f"{id} - Average frame processing time: {mean(frame_times)*1000:.2f}ms")
|
||||
|
||||
edgetpu_process = EdgeTPUProcess()
|
||||
|
||||
# start(1, 1000, edgetpu_process.detect_lock, edgetpu_process.detect_ready, edgetpu_process.frame_ready)
|
||||
|
||||
####
|
||||
# Multiple camera processes
|
||||
####
|
||||
camera_processes = []
|
||||
for x in range(0, 10):
|
||||
camera_process = mp.Process(target=start, args=(x, 100, edgetpu_process.detection_queue))
|
||||
camera_process.daemon = True
|
||||
camera_processes.append(camera_process)
|
||||
|
||||
start = datetime.datetime.now().timestamp()
|
||||
|
||||
for p in camera_processes:
|
||||
p.start()
|
||||
|
||||
for p in camera_processes:
|
||||
p.join()
|
||||
|
||||
duration = datetime.datetime.now().timestamp()-start
|
||||
print(f"Total - Processed for {duration:.2f} seconds.")
|
||||
@@ -1,189 +0,0 @@
|
||||
web_port: 5000
|
||||
|
||||
mqtt:
|
||||
host: mqtt.server.com
|
||||
topic_prefix: frigate
|
||||
# client_id: frigate # Optional -- set to override default client id of 'frigate' if running multiple instances
|
||||
# user: username # Optional
|
||||
#################
|
||||
## Environment variables that begin with 'FRIGATE_' may be referenced in {}.
|
||||
## password: '{FRIGATE_MQTT_PASSWORD}'
|
||||
#################
|
||||
# password: password # Optional
|
||||
|
||||
#################
|
||||
# Default ffmpeg args. Optional and can be overwritten per camera.
|
||||
# Should work with most RTSP cameras that send h264 video
|
||||
# Built from the properties below with:
|
||||
# "ffmpeg" + global_args + input_args + "-i" + input + output_args
|
||||
#################
|
||||
# ffmpeg:
|
||||
# global_args:
|
||||
# - -hide_banner
|
||||
# - -loglevel
|
||||
# - panic
|
||||
# hwaccel_args: []
|
||||
# input_args:
|
||||
# - -avoid_negative_ts
|
||||
# - make_zero
|
||||
# - -fflags
|
||||
# - nobuffer
|
||||
# - -flags
|
||||
# - low_delay
|
||||
# - -strict
|
||||
# - experimental
|
||||
# - -fflags
|
||||
# - +genpts+discardcorrupt
|
||||
# - -vsync
|
||||
# - drop
|
||||
# - -rtsp_transport
|
||||
# - tcp
|
||||
# - -stimeout
|
||||
# - '5000000'
|
||||
# - -use_wallclock_as_timestamps
|
||||
# - '1'
|
||||
# output_args:
|
||||
# - -f
|
||||
# - rawvideo
|
||||
# - -pix_fmt
|
||||
# - rgb24
|
||||
|
||||
####################
|
||||
# Global object configuration. Applies to all cameras
|
||||
# unless overridden at the camera levels.
|
||||
# Keys must be valid labels. By default, the model uses coco (https://dl.google.com/coral/canned_models/coco_labels.txt).
|
||||
# All labels from the model are reported over MQTT. These values are used to filter out false positives.
|
||||
# min_area (optional): minimum width*height of the bounding box for the detected person
|
||||
# max_area (optional): maximum width*height of the bounding box for the detected person
|
||||
# threshold (optional): The minimum decimal percentage (50% hit = 0.5) for the confidence from tensorflow
|
||||
####################
|
||||
objects:
|
||||
track:
|
||||
- person
|
||||
- car
|
||||
- truck
|
||||
filters:
|
||||
person:
|
||||
min_area: 5000
|
||||
max_area: 100000
|
||||
threshold: 0.8
|
||||
|
||||
zones:
|
||||
#################
|
||||
# Name of the zone
|
||||
################
|
||||
front_steps:
|
||||
cameras:
|
||||
front_door:
|
||||
####################
|
||||
# For each camera, a list of x,y coordinates to define the polygon of the zone. The top
|
||||
# left corner is 0,0. Can also be a comma separated string of all x,y coordinates combined.
|
||||
# The same zone can exist across multiple cameras if they have overlapping FOVs.
|
||||
# An object is determined to be in the zone based on whether or not the bottom center
|
||||
# of it's bounding box is within the polygon. The polygon must have at least 3 points.
|
||||
# Coordinates can be generated at https://www.image-map.net/
|
||||
####################
|
||||
coordinates:
|
||||
- 545,1077
|
||||
- 747,939
|
||||
- 788,805
|
||||
################
|
||||
# Zone level object filters. These are applied in addition to the global and camera filters
|
||||
# and should be more restrictive than the global and camera filters. The global and camera
|
||||
# filters are applied upstream.
|
||||
################
|
||||
filters:
|
||||
person:
|
||||
min_area: 5000
|
||||
max_area: 100000
|
||||
threshold: 0.8
|
||||
driveway:
|
||||
cameras:
|
||||
front_door:
|
||||
coordinates: 545,1077,747,939,788,805
|
||||
yard:
|
||||
|
||||
cameras:
|
||||
back:
|
||||
ffmpeg:
|
||||
################
|
||||
# Source passed to ffmpeg after the -i parameter. Supports anything compatible with OpenCV and FFmpeg.
|
||||
# Environment variables that begin with 'FRIGATE_' may be referenced in {}
|
||||
################
|
||||
input: rtsp://viewer:{FRIGATE_RTSP_PASSWORD}@10.0.10.10:554/cam/realmonitor?channel=1&subtype=2
|
||||
#################
|
||||
# These values will override default values for just this camera
|
||||
#################
|
||||
# global_args: []
|
||||
# hwaccel_args: []
|
||||
# input_args: []
|
||||
# output_args: []
|
||||
|
||||
################
|
||||
## Optionally specify the resolution of the video feed. Frigate will try to auto detect if not specified
|
||||
################
|
||||
# height: 1280
|
||||
# width: 720
|
||||
|
||||
################
|
||||
## Optional mask. Must be the same aspect ratio as your video feed. Value is either the
|
||||
## name of a file in the config directory or a base64 encoded bmp image prefixed with
|
||||
## 'base64,' eg. 'base64,asfasdfasdf....'.
|
||||
##
|
||||
## The mask works by looking at the bottom center of the bounding box for the detected
|
||||
## person in the image. If that pixel in the mask is a black pixel, it ignores it as a
|
||||
## false positive. In my mask, the grass and driveway visible from my backdoor camera
|
||||
## are white. The garage doors, sky, and trees (anywhere it would be impossible for a
|
||||
## person to stand) are black.
|
||||
##
|
||||
## Masked areas are also ignored for motion detection.
|
||||
################
|
||||
# mask: back-mask.bmp
|
||||
|
||||
################
|
||||
# Allows you to limit the framerate within frigate for cameras that do not support
|
||||
# custom framerates. A value of 1 tells frigate to look at every frame, 2 every 2nd frame,
|
||||
# 3 every 3rd frame, etc.
|
||||
################
|
||||
take_frame: 1
|
||||
|
||||
################
|
||||
# This will save a clip for each tracked object by frigate along with a json file that contains
|
||||
# data related to the tracked object. This works by telling ffmpeg to write video segments to /cache
|
||||
# from the video stream without re-encoding. Clips are then created by using ffmpeg to merge segments
|
||||
# without re-encoding. The segments saved are unaltered from what frigate receives to avoid re-encoding.
|
||||
# They do not contain bounding boxes. 30 seconds of video is added to the start of the clip. These are
|
||||
# optimized to capture "false_positive" examples for improving frigate.
|
||||
#
|
||||
# NOTE: This will only work for camera feeds that can be copied into the mp4 container format without
|
||||
# encoding such as h264. I do not expect this to work for mjpeg streams, and it may not work for many other
|
||||
# types of streams.
|
||||
#
|
||||
# WARNING: Videos in /cache are retained until there are no ongoing events. If you are tracking cars or
|
||||
# other objects for long periods of time, the cache will continue to grow indefinitely.
|
||||
################
|
||||
save_clips:
|
||||
enabled: False
|
||||
#########
|
||||
# Number of seconds before the event to include in the clips
|
||||
#########
|
||||
pre_capture: 30
|
||||
|
||||
################
|
||||
# Configuration for the snapshots in the debug view and mqtt
|
||||
################
|
||||
snapshots:
|
||||
show_timestamp: True
|
||||
draw_zones: False
|
||||
|
||||
################
|
||||
# Camera level object config. This config is merged with the global config above.
|
||||
################
|
||||
objects:
|
||||
track:
|
||||
- person
|
||||
filters:
|
||||
person:
|
||||
min_area: 5000
|
||||
max_area: 100000
|
||||
threshold: 0.8
|
||||
42
config/config.yml
Normal file
42
config/config.yml
Normal file
@@ -0,0 +1,42 @@
|
||||
web_port: 5000
|
||||
|
||||
mqtt:
|
||||
host: mqtt.server.com
|
||||
topic_prefix: frigate
|
||||
|
||||
cameras:
|
||||
back:
|
||||
rtsp:
|
||||
user: viewer
|
||||
host: 10.0.10.10
|
||||
port: 554
|
||||
# values that begin with a "$" will be replaced with environment variable
|
||||
password: $RTSP_PASSWORD
|
||||
path: /cam/realmonitor?channel=1&subtype=2
|
||||
regions:
|
||||
- size: 350
|
||||
x_offset: 0
|
||||
y_offset: 300
|
||||
- size: 400
|
||||
x_offset: 350
|
||||
y_offset: 250
|
||||
- size: 400
|
||||
x_offset: 750
|
||||
y_offset: 250
|
||||
mask: back-mask.bmp
|
||||
known_sizes:
|
||||
- y: 300
|
||||
min: 700
|
||||
max: 1800
|
||||
- y: 400
|
||||
min: 3000
|
||||
max: 7200
|
||||
- y: 500
|
||||
min: 8500
|
||||
max: 20400
|
||||
- y: 600
|
||||
min: 10000
|
||||
max: 50000
|
||||
- y: 700
|
||||
min: 10000
|
||||
max: 125000
|
||||
@@ -1,28 +1,13 @@
|
||||
import os
|
||||
import signal
|
||||
import sys
|
||||
import traceback
|
||||
import signal
|
||||
import cv2
|
||||
import time
|
||||
import datetime
|
||||
import queue
|
||||
import yaml
|
||||
import threading
|
||||
import multiprocessing as mp
|
||||
import subprocess as sp
|
||||
import numpy as np
|
||||
import logging
|
||||
from flask import Flask, Response, make_response, jsonify, request
|
||||
from flask import Flask, Response, make_response
|
||||
import paho.mqtt.client as mqtt
|
||||
|
||||
from frigate.video import track_camera, get_ffmpeg_input, get_frame_shape, CameraCapture, start_or_restart_ffmpeg
|
||||
from frigate.object_processing import TrackedObjectProcessor
|
||||
from frigate.events import EventProcessor
|
||||
from frigate.util import EventsPerSecond
|
||||
from frigate.edgetpu import EdgeTPUProcess
|
||||
|
||||
FRIGATE_VARS = {k: v for k, v in os.environ.items() if k.startswith('FRIGATE_')}
|
||||
from frigate.video import Camera
|
||||
from frigate.object_detection import PreppedQueueProcessor
|
||||
|
||||
with open('/config/config.yml') as f:
|
||||
CONFIG = yaml.safe_load(f)
|
||||
@@ -32,405 +17,74 @@ MQTT_PORT = CONFIG.get('mqtt', {}).get('port', 1883)
|
||||
MQTT_TOPIC_PREFIX = CONFIG.get('mqtt', {}).get('topic_prefix', 'frigate')
|
||||
MQTT_USER = CONFIG.get('mqtt', {}).get('user')
|
||||
MQTT_PASS = CONFIG.get('mqtt', {}).get('password')
|
||||
if not MQTT_PASS is None:
|
||||
MQTT_PASS = MQTT_PASS.format(**FRIGATE_VARS)
|
||||
MQTT_CLIENT_ID = CONFIG.get('mqtt', {}).get('client_id', 'frigate')
|
||||
|
||||
# Set the default FFmpeg config
|
||||
FFMPEG_CONFIG = CONFIG.get('ffmpeg', {})
|
||||
FFMPEG_DEFAULT_CONFIG = {
|
||||
'global_args': FFMPEG_CONFIG.get('global_args',
|
||||
['-hide_banner','-loglevel','panic']),
|
||||
'hwaccel_args': FFMPEG_CONFIG.get('hwaccel_args',
|
||||
[]),
|
||||
'input_args': FFMPEG_CONFIG.get('input_args',
|
||||
['-avoid_negative_ts', 'make_zero',
|
||||
'-fflags', 'nobuffer',
|
||||
'-flags', 'low_delay',
|
||||
'-strict', 'experimental',
|
||||
'-fflags', '+genpts+discardcorrupt',
|
||||
'-rtsp_transport', 'tcp',
|
||||
'-stimeout', '5000000',
|
||||
'-use_wallclock_as_timestamps', '1']),
|
||||
'output_args': FFMPEG_CONFIG.get('output_args',
|
||||
['-f', 'rawvideo',
|
||||
'-pix_fmt', 'rgb24'])
|
||||
}
|
||||
|
||||
GLOBAL_OBJECT_CONFIG = CONFIG.get('objects', {})
|
||||
|
||||
WEB_PORT = CONFIG.get('web_port', 5000)
|
||||
DEBUG = (CONFIG.get('debug', '0') == '1')
|
||||
|
||||
def start_plasma_store():
|
||||
plasma_cmd = ['plasma_store', '-m', '400000000', '-s', '/tmp/plasma']
|
||||
plasma_process = sp.Popen(plasma_cmd, stdout=sp.DEVNULL, stderr=sp.DEVNULL)
|
||||
time.sleep(1)
|
||||
rc = plasma_process.poll()
|
||||
if rc is not None:
|
||||
return None
|
||||
return plasma_process
|
||||
|
||||
class CameraWatchdog(threading.Thread):
|
||||
def __init__(self, camera_processes, config, tflite_process, tracked_objects_queue, plasma_process, stop_event):
|
||||
threading.Thread.__init__(self)
|
||||
self.camera_processes = camera_processes
|
||||
self.config = config
|
||||
self.tflite_process = tflite_process
|
||||
self.tracked_objects_queue = tracked_objects_queue
|
||||
self.plasma_process = plasma_process
|
||||
self.stop_event = stop_event
|
||||
|
||||
def run(self):
|
||||
time.sleep(10)
|
||||
while True:
|
||||
# wait a bit before checking
|
||||
time.sleep(10)
|
||||
|
||||
if self.stop_event.is_set():
|
||||
print(f"Exiting watchdog...")
|
||||
break
|
||||
|
||||
now = datetime.datetime.now().timestamp()
|
||||
|
||||
# check the plasma process
|
||||
rc = self.plasma_process.poll()
|
||||
if rc != None:
|
||||
print(f"plasma_process exited unexpectedly with {rc}")
|
||||
self.plasma_process = start_plasma_store()
|
||||
|
||||
# check the detection process
|
||||
detection_start = self.tflite_process.detection_start.value
|
||||
if (detection_start > 0.0 and
|
||||
now - detection_start > 10):
|
||||
print("Detection appears to be stuck. Restarting detection process")
|
||||
self.tflite_process.start_or_restart()
|
||||
elif not self.tflite_process.detect_process.is_alive():
|
||||
print("Detection appears to have stopped. Restarting detection process")
|
||||
self.tflite_process.start_or_restart()
|
||||
|
||||
# check the camera processes
|
||||
for name, camera_process in self.camera_processes.items():
|
||||
process = camera_process['process']
|
||||
if not process.is_alive():
|
||||
print(f"Track process for {name} is not alive. Starting again...")
|
||||
camera_process['process_fps'].value = 0.0
|
||||
camera_process['detection_fps'].value = 0.0
|
||||
camera_process['read_start'].value = 0.0
|
||||
process = mp.Process(target=track_camera, args=(name, self.config[name], GLOBAL_OBJECT_CONFIG, camera_process['frame_queue'],
|
||||
camera_process['frame_shape'], self.tflite_process.detection_queue, self.tracked_objects_queue,
|
||||
camera_process['process_fps'], camera_process['detection_fps'],
|
||||
camera_process['read_start'], camera_process['detection_frame']))
|
||||
process.daemon = True
|
||||
camera_process['process'] = process
|
||||
process.start()
|
||||
print(f"Track process started for {name}: {process.pid}")
|
||||
|
||||
if not camera_process['capture_thread'].is_alive():
|
||||
frame_shape = camera_process['frame_shape']
|
||||
frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
ffmpeg_process = start_or_restart_ffmpeg(camera_process['ffmpeg_cmd'], frame_size)
|
||||
camera_capture = CameraCapture(name, ffmpeg_process, frame_shape, camera_process['frame_queue'],
|
||||
camera_process['take_frame'], camera_process['camera_fps'], camera_process['detection_frame'], self.stop_event)
|
||||
camera_capture.start()
|
||||
camera_process['ffmpeg_process'] = ffmpeg_process
|
||||
camera_process['capture_thread'] = camera_capture
|
||||
elif now - camera_process['capture_thread'].current_frame > 5:
|
||||
print(f"No frames received from {name} in 5 seconds. Exiting ffmpeg...")
|
||||
ffmpeg_process = camera_process['ffmpeg_process']
|
||||
ffmpeg_process.terminate()
|
||||
try:
|
||||
print("Waiting for ffmpeg to exit gracefully...")
|
||||
ffmpeg_process.communicate(timeout=30)
|
||||
except sp.TimeoutExpired:
|
||||
print("FFmpeg didnt exit. Force killing...")
|
||||
ffmpeg_process.kill()
|
||||
ffmpeg_process.communicate()
|
||||
|
||||
def main():
|
||||
stop_event = threading.Event()
|
||||
# connect to mqtt and setup last will
|
||||
def on_connect(client, userdata, flags, rc):
|
||||
print("On connect called")
|
||||
if rc != 0:
|
||||
if rc == 3:
|
||||
print ("MQTT Server unavailable")
|
||||
elif rc == 4:
|
||||
print ("MQTT Bad username or password")
|
||||
elif rc == 5:
|
||||
print ("MQTT Not authorized")
|
||||
else:
|
||||
print ("Unable to connect to MQTT: Connection refused. Error code: " + str(rc))
|
||||
# publish a message to signal that the service is running
|
||||
client.publish(MQTT_TOPIC_PREFIX+'/available', 'online', retain=True)
|
||||
client = mqtt.Client(client_id=MQTT_CLIENT_ID)
|
||||
client = mqtt.Client()
|
||||
client.on_connect = on_connect
|
||||
client.will_set(MQTT_TOPIC_PREFIX+'/available', payload='offline', qos=1, retain=True)
|
||||
if not MQTT_USER is None:
|
||||
client.username_pw_set(MQTT_USER, password=MQTT_PASS)
|
||||
client.connect(MQTT_HOST, MQTT_PORT, 60)
|
||||
client.loop_start()
|
||||
|
||||
# Queue for prepped frames, max size set to (number of cameras * 5)
|
||||
max_queue_size = len(CONFIG['cameras'].items())*10
|
||||
prepped_frame_queue = queue.Queue(max_queue_size)
|
||||
|
||||
plasma_process = start_plasma_store()
|
||||
|
||||
##
|
||||
# Setup config defaults for cameras
|
||||
##
|
||||
cameras = {}
|
||||
for name, config in CONFIG['cameras'].items():
|
||||
config['snapshots'] = {
|
||||
'show_timestamp': config.get('snapshots', {}).get('show_timestamp', True),
|
||||
'draw_zones': config.get('snapshots', {}).get('draw_zones', False)
|
||||
}
|
||||
cameras[name] = Camera(name, config, prepped_frame_queue, client, MQTT_TOPIC_PREFIX, DEBUG)
|
||||
|
||||
# Queue for cameras to push tracked objects to
|
||||
tracked_objects_queue = mp.Queue()
|
||||
prepped_queue_processor = PreppedQueueProcessor(
|
||||
cameras,
|
||||
prepped_frame_queue
|
||||
)
|
||||
prepped_queue_processor.start()
|
||||
|
||||
# Queue for clip processing
|
||||
event_queue = mp.Queue()
|
||||
|
||||
# Start the shared tflite process
|
||||
tflite_process = EdgeTPUProcess()
|
||||
|
||||
# start the camera processes
|
||||
camera_processes = {}
|
||||
for name, config in CONFIG['cameras'].items():
|
||||
# Merge the ffmpeg config with the global config
|
||||
ffmpeg = config.get('ffmpeg', {})
|
||||
ffmpeg_input = get_ffmpeg_input(ffmpeg['input'])
|
||||
ffmpeg_global_args = ffmpeg.get('global_args', FFMPEG_DEFAULT_CONFIG['global_args'])
|
||||
ffmpeg_hwaccel_args = ffmpeg.get('hwaccel_args', FFMPEG_DEFAULT_CONFIG['hwaccel_args'])
|
||||
ffmpeg_input_args = ffmpeg.get('input_args', FFMPEG_DEFAULT_CONFIG['input_args'])
|
||||
ffmpeg_output_args = ffmpeg.get('output_args', FFMPEG_DEFAULT_CONFIG['output_args'])
|
||||
if config.get('save_clips', {}).get('enabled', False):
|
||||
ffmpeg_output_args = [
|
||||
"-f",
|
||||
"segment",
|
||||
"-segment_time",
|
||||
"10",
|
||||
"-segment_format",
|
||||
"mp4",
|
||||
"-reset_timestamps",
|
||||
"1",
|
||||
"-strftime",
|
||||
"1",
|
||||
"-c",
|
||||
"copy",
|
||||
"-an",
|
||||
"-map",
|
||||
"0",
|
||||
f"/cache/{name}-%Y%m%d%H%M%S.mp4"
|
||||
] + ffmpeg_output_args
|
||||
ffmpeg_cmd = (['ffmpeg'] +
|
||||
ffmpeg_global_args +
|
||||
ffmpeg_hwaccel_args +
|
||||
ffmpeg_input_args +
|
||||
['-i', ffmpeg_input] +
|
||||
ffmpeg_output_args +
|
||||
['pipe:'])
|
||||
|
||||
if 'width' in config and 'height' in config:
|
||||
frame_shape = (config['height'], config['width'], 3)
|
||||
else:
|
||||
frame_shape = get_frame_shape(ffmpeg_input)
|
||||
|
||||
frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
take_frame = config.get('take_frame', 1)
|
||||
|
||||
detection_frame = mp.Value('d', 0.0)
|
||||
|
||||
ffmpeg_process = start_or_restart_ffmpeg(ffmpeg_cmd, frame_size)
|
||||
frame_queue = mp.Queue()
|
||||
camera_fps = EventsPerSecond()
|
||||
camera_fps.start()
|
||||
camera_capture = CameraCapture(name, ffmpeg_process, frame_shape, frame_queue, take_frame, camera_fps, detection_frame, stop_event)
|
||||
camera_capture.start()
|
||||
|
||||
camera_processes[name] = {
|
||||
'camera_fps': camera_fps,
|
||||
'take_frame': take_frame,
|
||||
'process_fps': mp.Value('d', 0.0),
|
||||
'detection_fps': mp.Value('d', 0.0),
|
||||
'detection_frame': detection_frame,
|
||||
'read_start': mp.Value('d', 0.0),
|
||||
'ffmpeg_process': ffmpeg_process,
|
||||
'ffmpeg_cmd': ffmpeg_cmd,
|
||||
'frame_queue': frame_queue,
|
||||
'frame_shape': frame_shape,
|
||||
'capture_thread': camera_capture
|
||||
}
|
||||
|
||||
camera_process = mp.Process(target=track_camera, args=(name, config, GLOBAL_OBJECT_CONFIG, frame_queue, frame_shape,
|
||||
tflite_process.detection_queue, tracked_objects_queue, camera_processes[name]['process_fps'],
|
||||
camera_processes[name]['detection_fps'],
|
||||
camera_processes[name]['read_start'], camera_processes[name]['detection_frame']))
|
||||
camera_process.daemon = True
|
||||
camera_processes[name]['process'] = camera_process
|
||||
|
||||
for name, camera_process in camera_processes.items():
|
||||
camera_process['process'].start()
|
||||
print(f"Camera_process started for {name}: {camera_process['process'].pid}")
|
||||
|
||||
event_processor = EventProcessor(CONFIG['cameras'], camera_processes, '/cache', '/clips', event_queue, stop_event)
|
||||
event_processor.start()
|
||||
|
||||
object_processor = TrackedObjectProcessor(CONFIG['cameras'], CONFIG.get('zones', {}), client, MQTT_TOPIC_PREFIX, tracked_objects_queue, event_queue,stop_event)
|
||||
object_processor.start()
|
||||
|
||||
camera_watchdog = CameraWatchdog(camera_processes, CONFIG['cameras'], tflite_process, tracked_objects_queue, plasma_process, stop_event)
|
||||
camera_watchdog.start()
|
||||
|
||||
def receiveSignal(signalNumber, frame):
|
||||
print('Received:', signalNumber)
|
||||
stop_event.set()
|
||||
event_processor.join()
|
||||
object_processor.join()
|
||||
camera_watchdog.join()
|
||||
for name, camera_process in camera_processes.items():
|
||||
camera_process['capture_thread'].join()
|
||||
rc = camera_watchdog.plasma_process.poll()
|
||||
if rc == None:
|
||||
camera_watchdog.plasma_process.terminate()
|
||||
sys.exit()
|
||||
|
||||
signal.signal(signal.SIGTERM, receiveSignal)
|
||||
signal.signal(signal.SIGINT, receiveSignal)
|
||||
for name, camera in cameras.items():
|
||||
camera.start()
|
||||
print("Capture process for {}: {}".format(name, camera.get_capture_pid()))
|
||||
|
||||
# create a flask app that encodes frames a mjpeg on demand
|
||||
app = Flask(__name__)
|
||||
log = logging.getLogger('werkzeug')
|
||||
log.setLevel(logging.ERROR)
|
||||
|
||||
@app.route('/')
|
||||
def ishealthy():
|
||||
# return a healh
|
||||
return "Frigate is running. Alive and healthy!"
|
||||
|
||||
@app.route('/debug/stack')
|
||||
def processor_stack():
|
||||
frame = sys._current_frames().get(object_processor.ident, None)
|
||||
if frame:
|
||||
return "<br>".join(traceback.format_stack(frame)), 200
|
||||
else:
|
||||
return "no frame found", 200
|
||||
|
||||
@app.route('/debug/print_stack')
|
||||
def print_stack():
|
||||
pid = int(request.args.get('pid', 0))
|
||||
if pid == 0:
|
||||
return "missing pid", 200
|
||||
else:
|
||||
os.kill(pid, signal.SIGUSR1)
|
||||
return "check logs", 200
|
||||
|
||||
@app.route('/debug/stats')
|
||||
def stats():
|
||||
stats = {}
|
||||
|
||||
total_detection_fps = 0
|
||||
|
||||
for name, camera_stats in camera_processes.items():
|
||||
total_detection_fps += camera_stats['detection_fps'].value
|
||||
capture_thread = camera_stats['capture_thread']
|
||||
stats[name] = {
|
||||
'camera_fps': round(capture_thread.fps.eps(), 2),
|
||||
'process_fps': round(camera_stats['process_fps'].value, 2),
|
||||
'skipped_fps': round(capture_thread.skipped_fps.eps(), 2),
|
||||
'detection_fps': round(camera_stats['detection_fps'].value, 2),
|
||||
'read_start': camera_stats['read_start'].value,
|
||||
'pid': camera_stats['process'].pid,
|
||||
'ffmpeg_pid': camera_stats['ffmpeg_process'].pid,
|
||||
'frame_info': {
|
||||
'read': capture_thread.current_frame,
|
||||
'detect': camera_stats['detection_frame'].value,
|
||||
'process': object_processor.camera_data[name]['current_frame_time']
|
||||
}
|
||||
}
|
||||
|
||||
stats['coral'] = {
|
||||
'fps': round(total_detection_fps, 2),
|
||||
'inference_speed': round(tflite_process.avg_inference_speed.value*1000, 2),
|
||||
'detection_start': tflite_process.detection_start.value,
|
||||
'pid': tflite_process.detect_process.pid
|
||||
}
|
||||
|
||||
rc = camera_watchdog.plasma_process.poll()
|
||||
stats['plasma_store_rc'] = rc
|
||||
|
||||
return jsonify(stats)
|
||||
|
||||
@app.route('/<camera_name>/<label>/best.jpg')
|
||||
def best(camera_name, label):
|
||||
if camera_name in CONFIG['cameras']:
|
||||
best_frame = object_processor.get_best(camera_name, label)
|
||||
if best_frame is None:
|
||||
best_frame = np.zeros((720,1280,3), np.uint8)
|
||||
|
||||
height = int(request.args.get('h', str(best_frame.shape[0])))
|
||||
width = int(height*best_frame.shape[1]/best_frame.shape[0])
|
||||
|
||||
best_frame = cv2.resize(best_frame, dsize=(width, height), interpolation=cv2.INTER_AREA)
|
||||
best_frame = cv2.cvtColor(best_frame, cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
response = make_response(jpg.tobytes())
|
||||
response.headers['Content-Type'] = 'image/jpg'
|
||||
return response
|
||||
else:
|
||||
return "Camera named {} not found".format(camera_name), 404
|
||||
@app.route('/<camera_name>/best_person.jpg')
|
||||
def best_person(camera_name):
|
||||
best_person_frame = cameras[camera_name].get_best_person()
|
||||
if best_person_frame is None:
|
||||
best_person_frame = np.zeros((720,1280,3), np.uint8)
|
||||
ret, jpg = cv2.imencode('.jpg', best_person_frame)
|
||||
response = make_response(jpg.tobytes())
|
||||
response.headers['Content-Type'] = 'image/jpg'
|
||||
return response
|
||||
|
||||
@app.route('/<camera_name>')
|
||||
def mjpeg_feed(camera_name):
|
||||
fps = int(request.args.get('fps', '3'))
|
||||
height = int(request.args.get('h', '360'))
|
||||
if camera_name in CONFIG['cameras']:
|
||||
# return a multipart response
|
||||
return Response(imagestream(camera_name, fps, height),
|
||||
mimetype='multipart/x-mixed-replace; boundary=frame')
|
||||
else:
|
||||
return "Camera named {} not found".format(camera_name), 404
|
||||
|
||||
@app.route('/<camera_name>/latest.jpg')
|
||||
def latest_frame(camera_name):
|
||||
if camera_name in CONFIG['cameras']:
|
||||
# max out at specified FPS
|
||||
frame = object_processor.get_current_frame(camera_name)
|
||||
if frame is None:
|
||||
frame = np.zeros((720,1280,3), np.uint8)
|
||||
# return a multipart response
|
||||
return Response(imagestream(camera_name),
|
||||
mimetype='multipart/x-mixed-replace; boundary=frame')
|
||||
|
||||
height = int(request.args.get('h', str(frame.shape[0])))
|
||||
width = int(height*frame.shape[1]/frame.shape[0])
|
||||
|
||||
frame = cv2.resize(frame, dsize=(width, height), interpolation=cv2.INTER_AREA)
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
ret, jpg = cv2.imencode('.jpg', frame)
|
||||
response = make_response(jpg.tobytes())
|
||||
response.headers['Content-Type'] = 'image/jpg'
|
||||
return response
|
||||
else:
|
||||
return "Camera named {} not found".format(camera_name), 404
|
||||
|
||||
def imagestream(camera_name, fps, height):
|
||||
def imagestream(camera_name):
|
||||
while True:
|
||||
# max out at specified FPS
|
||||
time.sleep(1/fps)
|
||||
frame = object_processor.get_current_frame(camera_name)
|
||||
if frame is None:
|
||||
frame = np.zeros((height,int(height*16/9),3), np.uint8)
|
||||
|
||||
width = int(height*frame.shape[1]/frame.shape[0])
|
||||
|
||||
frame = cv2.resize(frame, dsize=(width, height), interpolation=cv2.INTER_LINEAR)
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
# max out at 5 FPS
|
||||
time.sleep(0.2)
|
||||
frame = cameras[camera_name].get_current_frame_with_objects()
|
||||
# encode the image into a jpg
|
||||
ret, jpg = cv2.imencode('.jpg', frame)
|
||||
yield (b'--frame\r\n'
|
||||
b'Content-Type: image/jpeg\r\n\r\n' + jpg.tobytes() + b'\r\n\r\n')
|
||||
|
||||
app.run(host='0.0.0.0', port=WEB_PORT, debug=False)
|
||||
|
||||
object_processor.join()
|
||||
|
||||
plasma_process.terminate()
|
||||
camera.join()
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
main()
|
||||
BIN
diagram.png
BIN
diagram.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 132 KiB After Width: | Height: | Size: 283 KiB |
@@ -1,74 +0,0 @@
|
||||
# Configuration Examples
|
||||
|
||||
### Default (most RTSP cameras)
|
||||
This is the default ffmpeg command and should work with most RTSP cameras that send h264 video
|
||||
```yaml
|
||||
ffmpeg:
|
||||
global_args:
|
||||
- -hide_banner
|
||||
- -loglevel
|
||||
- panic
|
||||
hwaccel_args: []
|
||||
input_args:
|
||||
- -avoid_negative_ts
|
||||
- make_zero
|
||||
- -fflags
|
||||
- nobuffer
|
||||
- -flags
|
||||
- low_delay
|
||||
- -strict
|
||||
- experimental
|
||||
- -fflags
|
||||
- +genpts+discardcorrupt
|
||||
- -vsync
|
||||
- drop
|
||||
- -rtsp_transport
|
||||
- tcp
|
||||
- -stimeout
|
||||
- '5000000'
|
||||
- -use_wallclock_as_timestamps
|
||||
- '1'
|
||||
output_args:
|
||||
- -vf
|
||||
- mpdecimate
|
||||
- -f
|
||||
- rawvideo
|
||||
- -pix_fmt
|
||||
- rgb24
|
||||
```
|
||||
|
||||
### RTMP Cameras
|
||||
The input parameters need to be adjusted for RTMP cameras
|
||||
```yaml
|
||||
ffmpeg:
|
||||
input_args:
|
||||
- -avoid_negative_ts
|
||||
- make_zero
|
||||
- -fflags
|
||||
- nobuffer
|
||||
- -flags
|
||||
- low_delay
|
||||
- -strict
|
||||
- experimental
|
||||
- -fflags
|
||||
- +genpts+discardcorrupt
|
||||
- -vsync
|
||||
- drop
|
||||
- -use_wallclock_as_timestamps
|
||||
- '1'
|
||||
```
|
||||
|
||||
|
||||
### Hardware Acceleration
|
||||
|
||||
Intel Quicksync
|
||||
```yaml
|
||||
ffmpeg:
|
||||
hwaccel_args:
|
||||
- -hwaccel
|
||||
- vaapi
|
||||
- -hwaccel_device
|
||||
- /dev/dri/renderD128
|
||||
- -hwaccel_output_format
|
||||
- yuv420p
|
||||
```
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 2.2 MiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 2.1 MiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 6.0 MiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 73 KiB |
@@ -1,142 +0,0 @@
|
||||
import os
|
||||
import datetime
|
||||
import hashlib
|
||||
import multiprocessing as mp
|
||||
import numpy as np
|
||||
import pyarrow.plasma as plasma
|
||||
import tflite_runtime.interpreter as tflite
|
||||
from tflite_runtime.interpreter import load_delegate
|
||||
from frigate.util import EventsPerSecond, listen
|
||||
|
||||
def load_labels(path, encoding='utf-8'):
|
||||
"""Loads labels from file (with or without index numbers).
|
||||
Args:
|
||||
path: path to label file.
|
||||
encoding: label file encoding.
|
||||
Returns:
|
||||
Dictionary mapping indices to labels.
|
||||
"""
|
||||
with open(path, 'r', encoding=encoding) as f:
|
||||
lines = f.readlines()
|
||||
if not lines:
|
||||
return {}
|
||||
|
||||
if lines[0].split(' ', maxsplit=1)[0].isdigit():
|
||||
pairs = [line.split(' ', maxsplit=1) for line in lines]
|
||||
return {int(index): label.strip() for index, label in pairs}
|
||||
else:
|
||||
return {index: line.strip() for index, line in enumerate(lines)}
|
||||
|
||||
class ObjectDetector():
|
||||
def __init__(self):
|
||||
edge_tpu_delegate = None
|
||||
try:
|
||||
edge_tpu_delegate = load_delegate('libedgetpu.so.1.0')
|
||||
except ValueError:
|
||||
print("No EdgeTPU detected. Falling back to CPU.")
|
||||
|
||||
if edge_tpu_delegate is None:
|
||||
self.interpreter = tflite.Interpreter(
|
||||
model_path='/cpu_model.tflite')
|
||||
else:
|
||||
self.interpreter = tflite.Interpreter(
|
||||
model_path='/edgetpu_model.tflite',
|
||||
experimental_delegates=[edge_tpu_delegate])
|
||||
|
||||
self.interpreter.allocate_tensors()
|
||||
|
||||
self.tensor_input_details = self.interpreter.get_input_details()
|
||||
self.tensor_output_details = self.interpreter.get_output_details()
|
||||
|
||||
def detect_raw(self, tensor_input):
|
||||
self.interpreter.set_tensor(self.tensor_input_details[0]['index'], tensor_input)
|
||||
self.interpreter.invoke()
|
||||
boxes = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[0]['index']))
|
||||
label_codes = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[1]['index']))
|
||||
scores = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[2]['index']))
|
||||
|
||||
detections = np.zeros((20,6), np.float32)
|
||||
for i, score in enumerate(scores):
|
||||
detections[i] = [label_codes[i], score, boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]]
|
||||
|
||||
return detections
|
||||
|
||||
def run_detector(detection_queue, avg_speed, start):
|
||||
print(f"Starting detection process: {os.getpid()}")
|
||||
listen()
|
||||
plasma_client = plasma.connect("/tmp/plasma")
|
||||
object_detector = ObjectDetector()
|
||||
|
||||
while True:
|
||||
object_id_str = detection_queue.get()
|
||||
object_id_hash = hashlib.sha1(str.encode(object_id_str))
|
||||
object_id = plasma.ObjectID(object_id_hash.digest())
|
||||
object_id_out = plasma.ObjectID(hashlib.sha1(str.encode(f"out-{object_id_str}")).digest())
|
||||
input_frame = plasma_client.get(object_id, timeout_ms=0)
|
||||
|
||||
if input_frame is plasma.ObjectNotAvailable:
|
||||
continue
|
||||
|
||||
# detect and put the output in the plasma store
|
||||
start.value = datetime.datetime.now().timestamp()
|
||||
plasma_client.put(object_detector.detect_raw(input_frame), object_id_out)
|
||||
duration = datetime.datetime.now().timestamp()-start.value
|
||||
start.value = 0.0
|
||||
|
||||
avg_speed.value = (avg_speed.value*9 + duration)/10
|
||||
|
||||
class EdgeTPUProcess():
|
||||
def __init__(self):
|
||||
self.detection_queue = mp.Queue()
|
||||
self.avg_inference_speed = mp.Value('d', 0.01)
|
||||
self.detection_start = mp.Value('d', 0.0)
|
||||
self.detect_process = None
|
||||
self.start_or_restart()
|
||||
|
||||
def start_or_restart(self):
|
||||
self.detection_start.value = 0.0
|
||||
if (not self.detect_process is None) and self.detect_process.is_alive():
|
||||
self.detect_process.terminate()
|
||||
print("Waiting for detection process to exit gracefully...")
|
||||
self.detect_process.join(timeout=30)
|
||||
if self.detect_process.exitcode is None:
|
||||
print("Detection process didnt exit. Force killing...")
|
||||
self.detect_process.kill()
|
||||
self.detect_process.join()
|
||||
self.detect_process = mp.Process(target=run_detector, args=(self.detection_queue, self.avg_inference_speed, self.detection_start))
|
||||
self.detect_process.daemon = True
|
||||
self.detect_process.start()
|
||||
|
||||
class RemoteObjectDetector():
|
||||
def __init__(self, name, labels, detection_queue):
|
||||
self.labels = load_labels(labels)
|
||||
self.name = name
|
||||
self.fps = EventsPerSecond()
|
||||
self.plasma_client = plasma.connect("/tmp/plasma")
|
||||
self.detection_queue = detection_queue
|
||||
|
||||
def detect(self, tensor_input, threshold=.4):
|
||||
detections = []
|
||||
|
||||
now = f"{self.name}-{str(datetime.datetime.now().timestamp())}"
|
||||
object_id_frame = plasma.ObjectID(hashlib.sha1(str.encode(now)).digest())
|
||||
object_id_detections = plasma.ObjectID(hashlib.sha1(str.encode(f"out-{now}")).digest())
|
||||
self.plasma_client.put(tensor_input, object_id_frame)
|
||||
self.detection_queue.put(now)
|
||||
raw_detections = self.plasma_client.get(object_id_detections, timeout_ms=10000)
|
||||
|
||||
if raw_detections is plasma.ObjectNotAvailable:
|
||||
self.plasma_client.delete([object_id_frame])
|
||||
return detections
|
||||
|
||||
for d in raw_detections:
|
||||
if d[1] < threshold:
|
||||
break
|
||||
detections.append((
|
||||
self.labels[int(d[0])],
|
||||
float(d[1]),
|
||||
(d[2], d[3], d[4], d[5])
|
||||
))
|
||||
self.plasma_client.delete([object_id_frame, object_id_detections])
|
||||
self.fps.update()
|
||||
return detections
|
||||
@@ -1,158 +0,0 @@
|
||||
import os
|
||||
import time
|
||||
import psutil
|
||||
import threading
|
||||
from collections import defaultdict
|
||||
import json
|
||||
import datetime
|
||||
import subprocess as sp
|
||||
import queue
|
||||
|
||||
class EventProcessor(threading.Thread):
|
||||
def __init__(self, config, camera_processes, cache_dir, clip_dir, event_queue, stop_event):
|
||||
threading.Thread.__init__(self)
|
||||
self.config = config
|
||||
self.camera_processes = camera_processes
|
||||
self.cache_dir = cache_dir
|
||||
self.clip_dir = clip_dir
|
||||
self.cached_clips = {}
|
||||
self.event_queue = event_queue
|
||||
self.events_in_process = {}
|
||||
self.stop_event = stop_event
|
||||
|
||||
def refresh_cache(self):
|
||||
cached_files = os.listdir(self.cache_dir)
|
||||
|
||||
files_in_use = []
|
||||
for process_data in self.camera_processes.values():
|
||||
try:
|
||||
ffmpeg_process = psutil.Process(pid=process_data['ffmpeg_process'].pid)
|
||||
flist = ffmpeg_process.open_files()
|
||||
if flist:
|
||||
for nt in flist:
|
||||
if nt.path.startswith(self.cache_dir):
|
||||
files_in_use.append(nt.path.split('/')[-1])
|
||||
except:
|
||||
continue
|
||||
|
||||
for f in cached_files:
|
||||
if f in files_in_use or f in self.cached_clips:
|
||||
continue
|
||||
|
||||
camera = '-'.join(f.split('-')[:-1])
|
||||
start_time = datetime.datetime.strptime(f.split('-')[-1].split('.')[0], '%Y%m%d%H%M%S')
|
||||
|
||||
ffprobe_cmd = " ".join([
|
||||
'ffprobe',
|
||||
'-v',
|
||||
'error',
|
||||
'-show_entries',
|
||||
'format=duration',
|
||||
'-of',
|
||||
'default=noprint_wrappers=1:nokey=1',
|
||||
f"{os.path.join(self.cache_dir,f)}"
|
||||
])
|
||||
p = sp.Popen(ffprobe_cmd, stdout=sp.PIPE, shell=True)
|
||||
(output, err) = p.communicate()
|
||||
p_status = p.wait()
|
||||
if p_status == 0:
|
||||
duration = float(output.decode('utf-8').strip())
|
||||
else:
|
||||
print(f"bad file: {f}")
|
||||
os.remove(os.path.join(self.cache_dir,f))
|
||||
continue
|
||||
|
||||
self.cached_clips[f] = {
|
||||
'path': f,
|
||||
'camera': camera,
|
||||
'start_time': start_time.timestamp(),
|
||||
'duration': duration
|
||||
}
|
||||
|
||||
if len(self.events_in_process) > 0:
|
||||
earliest_event = min(self.events_in_process.values(), key=lambda x:x['start_time'])['start_time']
|
||||
else:
|
||||
earliest_event = datetime.datetime.now().timestamp()
|
||||
|
||||
for f, data in list(self.cached_clips.items()):
|
||||
if earliest_event-90 > data['start_time']+data['duration']:
|
||||
del self.cached_clips[f]
|
||||
os.remove(os.path.join(self.cache_dir,f))
|
||||
|
||||
def create_clip(self, camera, event_data, pre_capture):
|
||||
# get all clips from the camera with the event sorted
|
||||
sorted_clips = sorted([c for c in self.cached_clips.values() if c['camera'] == camera], key = lambda i: i['start_time'])
|
||||
|
||||
while sorted_clips[-1]['start_time'] + sorted_clips[-1]['duration'] < event_data['end_time']:
|
||||
time.sleep(5)
|
||||
self.refresh_cache()
|
||||
# get all clips from the camera with the event sorted
|
||||
sorted_clips = sorted([c for c in self.cached_clips.values() if c['camera'] == camera], key = lambda i: i['start_time'])
|
||||
|
||||
playlist_start = event_data['start_time']-pre_capture
|
||||
playlist_end = event_data['end_time']+5
|
||||
playlist_lines = []
|
||||
for clip in sorted_clips:
|
||||
# clip ends before playlist start time, skip
|
||||
if clip['start_time']+clip['duration'] < playlist_start:
|
||||
continue
|
||||
# clip starts after playlist ends, finish
|
||||
if clip['start_time'] > playlist_end:
|
||||
break
|
||||
playlist_lines.append(f"file '{os.path.join(self.cache_dir,clip['path'])}'")
|
||||
# if this is the starting clip, add an inpoint
|
||||
if clip['start_time'] < playlist_start:
|
||||
playlist_lines.append(f"inpoint {int(playlist_start-clip['start_time'])}")
|
||||
# if this is the ending clip, add an outpoint
|
||||
if clip['start_time']+clip['duration'] > playlist_end:
|
||||
playlist_lines.append(f"outpoint {int(playlist_end-clip['start_time'])}")
|
||||
|
||||
clip_name = f"{camera}-{event_data['id']}"
|
||||
ffmpeg_cmd = [
|
||||
'ffmpeg',
|
||||
'-y',
|
||||
'-protocol_whitelist',
|
||||
'pipe,file',
|
||||
'-f',
|
||||
'concat',
|
||||
'-safe',
|
||||
'0',
|
||||
'-i',
|
||||
'-',
|
||||
'-c',
|
||||
'copy',
|
||||
f"{os.path.join(self.clip_dir, clip_name)}.mp4"
|
||||
]
|
||||
|
||||
p = sp.run(ffmpeg_cmd, input="\n".join(playlist_lines), encoding='ascii', capture_output=True)
|
||||
if p.returncode != 0:
|
||||
print(p.stderr)
|
||||
return
|
||||
|
||||
with open(f"{os.path.join(self.clip_dir, clip_name)}.json", 'w') as outfile:
|
||||
json.dump(event_data, outfile)
|
||||
|
||||
def run(self):
|
||||
while True:
|
||||
if self.stop_event.is_set():
|
||||
print(f"Exiting event processor...")
|
||||
break
|
||||
|
||||
try:
|
||||
event_type, camera, event_data = self.event_queue.get(timeout=10)
|
||||
except queue.Empty:
|
||||
if not self.stop_event.is_set():
|
||||
self.refresh_cache()
|
||||
continue
|
||||
|
||||
self.refresh_cache()
|
||||
|
||||
if event_type == 'start':
|
||||
self.events_in_process[event_data['id']] = event_data
|
||||
|
||||
if event_type == 'end':
|
||||
if self.config[camera].get('save_clips', {}).get('enabled', False) and len(self.cached_clips) > 0:
|
||||
self.create_clip(camera, event_data, self.config[camera].get('save_clips', {}).get('pre_capture', 30))
|
||||
del self.events_in_process[event_data['id']]
|
||||
|
||||
|
||||
@@ -1,79 +0,0 @@
|
||||
import cv2
|
||||
import imutils
|
||||
import numpy as np
|
||||
|
||||
class MotionDetector():
|
||||
def __init__(self, frame_shape, mask, resize_factor=4):
|
||||
self.resize_factor = resize_factor
|
||||
self.motion_frame_size = (int(frame_shape[0]/resize_factor), int(frame_shape[1]/resize_factor))
|
||||
self.avg_frame = np.zeros(self.motion_frame_size, np.float)
|
||||
self.avg_delta = np.zeros(self.motion_frame_size, np.float)
|
||||
self.motion_frame_count = 0
|
||||
self.frame_counter = 0
|
||||
resized_mask = cv2.resize(mask, dsize=(self.motion_frame_size[1], self.motion_frame_size[0]), interpolation=cv2.INTER_LINEAR)
|
||||
self.mask = np.where(resized_mask==[0])
|
||||
|
||||
def detect(self, frame):
|
||||
motion_boxes = []
|
||||
|
||||
# resize frame
|
||||
resized_frame = cv2.resize(frame, dsize=(self.motion_frame_size[1], self.motion_frame_size[0]), interpolation=cv2.INTER_LINEAR)
|
||||
|
||||
# convert to grayscale
|
||||
gray = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# mask frame
|
||||
gray[self.mask] = [255]
|
||||
|
||||
# it takes ~30 frames to establish a baseline
|
||||
# dont bother looking for motion
|
||||
if self.frame_counter < 30:
|
||||
self.frame_counter += 1
|
||||
else:
|
||||
# compare to average
|
||||
frameDelta = cv2.absdiff(gray, cv2.convertScaleAbs(self.avg_frame))
|
||||
|
||||
# compute the average delta over the past few frames
|
||||
# the alpha value can be modified to configure how sensitive the motion detection is.
|
||||
# higher values mean the current frame impacts the delta a lot, and a single raindrop may
|
||||
# register as motion, too low and a fast moving person wont be detected as motion
|
||||
# this also assumes that a person is in the same location across more than a single frame
|
||||
cv2.accumulateWeighted(frameDelta, self.avg_delta, 0.2)
|
||||
|
||||
# compute the threshold image for the current frame
|
||||
current_thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1]
|
||||
|
||||
# black out everything in the avg_delta where there isnt motion in the current frame
|
||||
avg_delta_image = cv2.convertScaleAbs(self.avg_delta)
|
||||
avg_delta_image[np.where(current_thresh==[0])] = [0]
|
||||
|
||||
# then look for deltas above the threshold, but only in areas where there is a delta
|
||||
# in the current frame. this prevents deltas from previous frames from being included
|
||||
thresh = cv2.threshold(avg_delta_image, 25, 255, cv2.THRESH_BINARY)[1]
|
||||
|
||||
# dilate the thresholded image to fill in holes, then find contours
|
||||
# on thresholded image
|
||||
thresh = cv2.dilate(thresh, None, iterations=2)
|
||||
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
cnts = imutils.grab_contours(cnts)
|
||||
|
||||
# loop over the contours
|
||||
for c in cnts:
|
||||
# if the contour is big enough, count it as motion
|
||||
contour_area = cv2.contourArea(c)
|
||||
if contour_area > 100:
|
||||
x, y, w, h = cv2.boundingRect(c)
|
||||
motion_boxes.append((x*self.resize_factor, y*self.resize_factor, (x+w)*self.resize_factor, (y+h)*self.resize_factor))
|
||||
|
||||
if len(motion_boxes) > 0:
|
||||
self.motion_frame_count += 1
|
||||
# TODO: this really depends on FPS
|
||||
if self.motion_frame_count >= 10:
|
||||
# only average in the current frame if the difference persists for at least 3 frames
|
||||
cv2.accumulateWeighted(gray, self.avg_frame, 0.2)
|
||||
else:
|
||||
# when no motion, just keep averaging the frames together
|
||||
cv2.accumulateWeighted(gray, self.avg_frame, 0.2)
|
||||
self.motion_frame_count = 0
|
||||
|
||||
return motion_boxes
|
||||
33
frigate/mqtt.py
Normal file
33
frigate/mqtt.py
Normal file
@@ -0,0 +1,33 @@
|
||||
import json
|
||||
import threading
|
||||
|
||||
class MqttObjectPublisher(threading.Thread):
|
||||
def __init__(self, client, topic_prefix, objects_parsed, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self.client = client
|
||||
self.topic_prefix = topic_prefix
|
||||
self.objects_parsed = objects_parsed
|
||||
self._detected_objects = detected_objects
|
||||
|
||||
def run(self):
|
||||
last_sent_payload = ""
|
||||
while True:
|
||||
|
||||
# initialize the payload
|
||||
payload = {}
|
||||
|
||||
# wait until objects have been parsed
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.wait()
|
||||
|
||||
# add all the person scores in detected objects
|
||||
detected_objects = self._detected_objects.copy()
|
||||
person_score = sum([obj['score'] for obj in detected_objects if obj['name'] == 'person'])
|
||||
# if the person score is more than 100, set person to ON
|
||||
payload['person'] = 'ON' if int(person_score*100) > 100 else 'OFF'
|
||||
|
||||
# send message for objects if different
|
||||
new_payload = json.dumps(payload, sort_keys=True)
|
||||
if new_payload != last_sent_payload:
|
||||
last_sent_payload = new_payload
|
||||
self.client.publish(self.topic_prefix+'/objects', new_payload, retain=False)
|
||||
110
frigate/object_detection.py
Normal file
110
frigate/object_detection.py
Normal file
@@ -0,0 +1,110 @@
|
||||
import datetime
|
||||
import time
|
||||
import cv2
|
||||
import threading
|
||||
import numpy as np
|
||||
from edgetpu.detection.engine import DetectionEngine
|
||||
from . util import tonumpyarray
|
||||
|
||||
# Path to frozen detection graph. This is the actual model that is used for the object detection.
|
||||
PATH_TO_CKPT = '/frozen_inference_graph.pb'
|
||||
# List of the strings that is used to add correct label for each box.
|
||||
PATH_TO_LABELS = '/label_map.pbtext'
|
||||
|
||||
# Function to read labels from text files.
|
||||
def ReadLabelFile(file_path):
|
||||
with open(file_path, 'r') as f:
|
||||
lines = f.readlines()
|
||||
ret = {}
|
||||
for line in lines:
|
||||
pair = line.strip().split(maxsplit=1)
|
||||
ret[int(pair[0])] = pair[1].strip()
|
||||
return ret
|
||||
|
||||
class PreppedQueueProcessor(threading.Thread):
|
||||
def __init__(self, cameras, prepped_frame_queue):
|
||||
|
||||
threading.Thread.__init__(self)
|
||||
self.cameras = cameras
|
||||
self.prepped_frame_queue = prepped_frame_queue
|
||||
|
||||
# Load the edgetpu engine and labels
|
||||
self.engine = DetectionEngine(PATH_TO_CKPT)
|
||||
self.labels = ReadLabelFile(PATH_TO_LABELS)
|
||||
|
||||
def run(self):
|
||||
# process queue...
|
||||
while True:
|
||||
frame = self.prepped_frame_queue.get()
|
||||
|
||||
# Actual detection.
|
||||
objects = self.engine.DetectWithInputTensor(frame['frame'], threshold=0.5, top_k=3)
|
||||
# parse and pass detected objects back to the camera
|
||||
parsed_objects = []
|
||||
for obj in objects:
|
||||
box = obj.bounding_box.flatten().tolist()
|
||||
parsed_objects.append({
|
||||
'frame_time': frame['frame_time'],
|
||||
'name': str(self.labels[obj.label_id]),
|
||||
'score': float(obj.score),
|
||||
'xmin': int((box[0] * frame['region_size']) + frame['region_x_offset']),
|
||||
'ymin': int((box[1] * frame['region_size']) + frame['region_y_offset']),
|
||||
'xmax': int((box[2] * frame['region_size']) + frame['region_x_offset']),
|
||||
'ymax': int((box[3] * frame['region_size']) + frame['region_y_offset'])
|
||||
})
|
||||
self.cameras[frame['camera_name']].add_objects(parsed_objects)
|
||||
|
||||
|
||||
# should this be a region class?
|
||||
class FramePrepper(threading.Thread):
|
||||
def __init__(self, camera_name, shared_frame, frame_time, frame_ready,
|
||||
frame_lock,
|
||||
region_size, region_x_offset, region_y_offset,
|
||||
prepped_frame_queue):
|
||||
|
||||
threading.Thread.__init__(self)
|
||||
self.camera_name = camera_name
|
||||
self.shared_frame = shared_frame
|
||||
self.frame_time = frame_time
|
||||
self.frame_ready = frame_ready
|
||||
self.frame_lock = frame_lock
|
||||
self.region_size = region_size
|
||||
self.region_x_offset = region_x_offset
|
||||
self.region_y_offset = region_y_offset
|
||||
self.prepped_frame_queue = prepped_frame_queue
|
||||
|
||||
def run(self):
|
||||
frame_time = 0.0
|
||||
while True:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
|
||||
with self.frame_ready:
|
||||
# if there isnt a frame ready for processing or it is old, wait for a new frame
|
||||
if self.frame_time.value == frame_time or (now - self.frame_time.value) > 0.5:
|
||||
self.frame_ready.wait()
|
||||
|
||||
# make a copy of the cropped frame
|
||||
with self.frame_lock:
|
||||
cropped_frame = self.shared_frame[self.region_y_offset:self.region_y_offset+self.region_size, self.region_x_offset:self.region_x_offset+self.region_size].copy()
|
||||
frame_time = self.frame_time.value
|
||||
|
||||
# convert to RGB
|
||||
cropped_frame_rgb = cv2.cvtColor(cropped_frame, cv2.COLOR_BGR2RGB)
|
||||
# Resize to 300x300 if needed
|
||||
if cropped_frame_rgb.shape != (300, 300, 3):
|
||||
cropped_frame_rgb = cv2.resize(cropped_frame_rgb, dsize=(300, 300), interpolation=cv2.INTER_LINEAR)
|
||||
# Expand dimensions since the model expects images to have shape: [1, 300, 300, 3]
|
||||
frame_expanded = np.expand_dims(cropped_frame_rgb, axis=0)
|
||||
|
||||
# add the frame to the queue
|
||||
if not self.prepped_frame_queue.full():
|
||||
self.prepped_frame_queue.put({
|
||||
'camera_name': self.camera_name,
|
||||
'frame_time': frame_time,
|
||||
'frame': frame_expanded.flatten().copy(),
|
||||
'region_size': self.region_size,
|
||||
'region_x_offset': self.region_x_offset,
|
||||
'region_y_offset': self.region_y_offset
|
||||
})
|
||||
else:
|
||||
print("queue full. moving on")
|
||||
@@ -1,277 +0,0 @@
|
||||
import json
|
||||
import hashlib
|
||||
import datetime
|
||||
import time
|
||||
import copy
|
||||
import cv2
|
||||
import threading
|
||||
import queue
|
||||
import numpy as np
|
||||
from collections import Counter, defaultdict
|
||||
import itertools
|
||||
import pyarrow.plasma as plasma
|
||||
import matplotlib.pyplot as plt
|
||||
from frigate.util import draw_box_with_label, PlasmaManager
|
||||
from frigate.edgetpu import load_labels
|
||||
|
||||
PATH_TO_LABELS = '/labelmap.txt'
|
||||
|
||||
LABELS = load_labels(PATH_TO_LABELS)
|
||||
cmap = plt.cm.get_cmap('tab10', len(LABELS.keys()))
|
||||
|
||||
COLOR_MAP = {}
|
||||
for key, val in LABELS.items():
|
||||
COLOR_MAP[val] = tuple(int(round(255 * c)) for c in cmap(key)[:3])
|
||||
|
||||
def filter_false_positives(event):
|
||||
if len(event['history']) < 2:
|
||||
return True
|
||||
return False
|
||||
|
||||
def zone_filtered(obj, object_config):
|
||||
object_name = obj['label']
|
||||
object_filters = object_config.get('filters', {})
|
||||
|
||||
if object_name in object_filters:
|
||||
obj_settings = object_filters[object_name]
|
||||
|
||||
# if the min area is larger than the
|
||||
# detected object, don't add it to detected objects
|
||||
if obj_settings.get('min_area',-1) > obj['area']:
|
||||
return True
|
||||
|
||||
# if the detected object is larger than the
|
||||
# max area, don't add it to detected objects
|
||||
if obj_settings.get('max_area', 24000000) < obj['area']:
|
||||
return True
|
||||
|
||||
# if the score is lower than the threshold, skip
|
||||
if obj_settings.get('threshold', 0) > obj['score']:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
class TrackedObjectProcessor(threading.Thread):
|
||||
def __init__(self, camera_config, zone_config, client, topic_prefix, tracked_objects_queue, event_queue, stop_event):
|
||||
threading.Thread.__init__(self)
|
||||
self.camera_config = camera_config
|
||||
self.zone_config = zone_config
|
||||
self.client = client
|
||||
self.topic_prefix = topic_prefix
|
||||
self.tracked_objects_queue = tracked_objects_queue
|
||||
self.event_queue = event_queue
|
||||
self.stop_event = stop_event
|
||||
self.camera_data = defaultdict(lambda: {
|
||||
'best_objects': {},
|
||||
'object_status': defaultdict(lambda: defaultdict(lambda: 'OFF')),
|
||||
'tracked_objects': {},
|
||||
'current_frame': np.zeros((720,1280,3), np.uint8),
|
||||
'current_frame_time': 0.0,
|
||||
'object_id': None
|
||||
})
|
||||
self.zone_data = defaultdict(lambda: {
|
||||
'object_status': defaultdict(lambda: defaultdict(lambda: 'OFF')),
|
||||
'contours': {}
|
||||
})
|
||||
|
||||
# create zone contours
|
||||
for name, config in zone_config.items():
|
||||
for camera, camera_zone_config in config.items():
|
||||
coordinates = camera_zone_config['coordinates']
|
||||
if isinstance(coordinates, list):
|
||||
self.zone_data[name]['contours'][camera] = np.array([[int(p.split(',')[0]), int(p.split(',')[1])] for p in coordinates])
|
||||
elif isinstance(coordinates, str):
|
||||
points = coordinates.split(',')
|
||||
self.zone_data[name]['contours'][camera] = np.array([[int(points[i]), int(points[i+1])] for i in range(0, len(points), 2)])
|
||||
else:
|
||||
print(f"Unable to parse zone coordinates for {name} - {camera}")
|
||||
|
||||
# set colors for zones
|
||||
colors = plt.cm.get_cmap('tab10', len(self.zone_data.keys()))
|
||||
for i, zone in enumerate(self.zone_data.values()):
|
||||
zone['color'] = tuple(int(round(255 * c)) for c in colors(i)[:3])
|
||||
|
||||
self.plasma_client = PlasmaManager(self.stop_event)
|
||||
|
||||
def get_best(self, camera, label):
|
||||
if label in self.camera_data[camera]['best_objects']:
|
||||
return self.camera_data[camera]['best_objects'][label]['frame']
|
||||
else:
|
||||
return None
|
||||
|
||||
def get_current_frame(self, camera):
|
||||
return self.camera_data[camera]['current_frame']
|
||||
|
||||
def run(self):
|
||||
while True:
|
||||
if self.stop_event.is_set():
|
||||
print(f"Exiting object processor...")
|
||||
break
|
||||
|
||||
try:
|
||||
camera, frame_time, current_tracked_objects = self.tracked_objects_queue.get(True, 10)
|
||||
except queue.Empty:
|
||||
continue
|
||||
|
||||
camera_config = self.camera_config[camera]
|
||||
best_objects = self.camera_data[camera]['best_objects']
|
||||
current_object_status = self.camera_data[camera]['object_status']
|
||||
tracked_objects = self.camera_data[camera]['tracked_objects']
|
||||
|
||||
current_ids = current_tracked_objects.keys()
|
||||
previous_ids = tracked_objects.keys()
|
||||
removed_ids = list(set(previous_ids).difference(current_ids))
|
||||
new_ids = list(set(current_ids).difference(previous_ids))
|
||||
updated_ids = list(set(current_ids).intersection(previous_ids))
|
||||
|
||||
for id in new_ids:
|
||||
# only register the object here if we are sure it isnt a false positive
|
||||
if not filter_false_positives(current_tracked_objects[id]):
|
||||
tracked_objects[id] = current_tracked_objects[id]
|
||||
# publish events to mqtt
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/events/start", json.dumps(tracked_objects[id]), retain=False)
|
||||
self.event_queue.put(('start', camera, tracked_objects[id]))
|
||||
|
||||
for id in updated_ids:
|
||||
tracked_objects[id] = current_tracked_objects[id]
|
||||
|
||||
for id in removed_ids:
|
||||
# publish events to mqtt
|
||||
tracked_objects[id]['end_time'] = frame_time
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/events/end", json.dumps(tracked_objects[id]), retain=False)
|
||||
self.event_queue.put(('end', camera, tracked_objects[id]))
|
||||
del tracked_objects[id]
|
||||
|
||||
self.camera_data[camera]['current_frame_time'] = frame_time
|
||||
|
||||
# build a dict of objects in each zone for current camera
|
||||
current_objects_in_zones = defaultdict(lambda: [])
|
||||
for obj in tracked_objects.values():
|
||||
bottom_center = (obj['centroid'][0], obj['box'][3])
|
||||
# check each zone
|
||||
for name, zone in self.zone_data.items():
|
||||
current_contour = zone['contours'].get(camera, None)
|
||||
# if the current camera does not have a contour for this zone, skip
|
||||
if current_contour is None:
|
||||
continue
|
||||
# check if the object is in the zone and not filtered
|
||||
if (cv2.pointPolygonTest(current_contour, bottom_center, False) >= 0
|
||||
and not zone_filtered(obj, self.zone_config[name][camera].get('filters', {}))):
|
||||
current_objects_in_zones[name].append(obj['label'])
|
||||
|
||||
###
|
||||
# Draw tracked objects on the frame
|
||||
###
|
||||
current_frame = self.plasma_client.get(f"{camera}{frame_time}")
|
||||
|
||||
if not current_frame is plasma.ObjectNotAvailable:
|
||||
# draw the bounding boxes on the frame
|
||||
for obj in tracked_objects.values():
|
||||
thickness = 2
|
||||
color = COLOR_MAP[obj['label']]
|
||||
|
||||
if obj['frame_time'] != frame_time:
|
||||
thickness = 1
|
||||
color = (255,0,0)
|
||||
|
||||
# draw the bounding boxes on the frame
|
||||
box = obj['box']
|
||||
draw_box_with_label(current_frame, box[0], box[1], box[2], box[3], obj['label'], f"{int(obj['score']*100)}% {int(obj['area'])}", thickness=thickness, color=color)
|
||||
# draw the regions on the frame
|
||||
region = obj['region']
|
||||
cv2.rectangle(current_frame, (region[0], region[1]), (region[2], region[3]), (0,255,0), 1)
|
||||
|
||||
if camera_config['snapshots']['show_timestamp']:
|
||||
time_to_show = datetime.datetime.fromtimestamp(frame_time).strftime("%m/%d/%Y %H:%M:%S")
|
||||
cv2.putText(current_frame, time_to_show, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, fontScale=.8, color=(255, 255, 255), thickness=2)
|
||||
|
||||
if camera_config['snapshots']['draw_zones']:
|
||||
for name, zone in self.zone_data.items():
|
||||
thickness = 2 if len(current_objects_in_zones[name]) == 0 else 8
|
||||
if camera in zone['contours']:
|
||||
cv2.drawContours(current_frame, [zone['contours'][camera]], -1, zone['color'], thickness)
|
||||
|
||||
###
|
||||
# Set the current frame
|
||||
###
|
||||
self.camera_data[camera]['current_frame'] = current_frame
|
||||
|
||||
# delete the previous frame from the plasma store and update the object id
|
||||
if not self.camera_data[camera]['object_id'] is None:
|
||||
self.plasma_client.delete(self.camera_data[camera]['object_id'])
|
||||
self.camera_data[camera]['object_id'] = f"{camera}{frame_time}"
|
||||
|
||||
###
|
||||
# Maintain the highest scoring recent object and frame for each label
|
||||
###
|
||||
for obj in tracked_objects.values():
|
||||
# if the object wasn't seen on the current frame, skip it
|
||||
if obj['frame_time'] != frame_time:
|
||||
continue
|
||||
if obj['label'] in best_objects:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# if the object is a higher score than the current best score
|
||||
# or the current object is more than 1 minute old, use the new object
|
||||
if obj['score'] > best_objects[obj['label']]['score'] or (now - best_objects[obj['label']]['frame_time']) > 60:
|
||||
obj['frame'] = np.copy(self.camera_data[camera]['current_frame'])
|
||||
best_objects[obj['label']] = obj
|
||||
# send updated snapshot over mqtt
|
||||
best_frame = cv2.cvtColor(obj['frame'], cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
if ret:
|
||||
jpg_bytes = jpg.tobytes()
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj['label']}/snapshot", jpg_bytes, retain=True)
|
||||
else:
|
||||
obj['frame'] = np.copy(self.camera_data[camera]['current_frame'])
|
||||
best_objects[obj['label']] = obj
|
||||
|
||||
###
|
||||
# Report over MQTT
|
||||
###
|
||||
|
||||
# get the zones that are relevant for this camera
|
||||
relevant_zones = [zone for zone, config in self.zone_config.items() if camera in config]
|
||||
for zone in relevant_zones:
|
||||
# create the set of labels in the current frame and previously reported
|
||||
labels_for_zone = set(current_objects_in_zones[zone] + list(self.zone_data[zone]['object_status'][camera].keys()))
|
||||
# for each label
|
||||
for label in labels_for_zone:
|
||||
# compute the current 'ON' vs 'OFF' status by checking if any camera sees the object in the zone
|
||||
previous_state = any([c[label] == 'ON' for c in self.zone_data[zone]['object_status'].values()])
|
||||
self.zone_data[zone]['object_status'][camera][label] = 'ON' if label in current_objects_in_zones[zone] else 'OFF'
|
||||
new_state = any([c[label] == 'ON' for c in self.zone_data[zone]['object_status'].values()])
|
||||
# if the value is changing, send over MQTT
|
||||
if previous_state == False and new_state == True:
|
||||
self.client.publish(f"{self.topic_prefix}/{zone}/{label}", 'ON', retain=False)
|
||||
elif previous_state == True and new_state == False:
|
||||
self.client.publish(f"{self.topic_prefix}/{zone}/{label}", 'OFF', retain=False)
|
||||
|
||||
# count by type
|
||||
obj_counter = Counter()
|
||||
for obj in tracked_objects.values():
|
||||
obj_counter[obj['label']] += 1
|
||||
|
||||
# report on detected objects
|
||||
for obj_name, count in obj_counter.items():
|
||||
new_status = 'ON' if count > 0 else 'OFF'
|
||||
if new_status != current_object_status[obj_name]:
|
||||
current_object_status[obj_name] = new_status
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}", new_status, retain=False)
|
||||
# send the best snapshot over mqtt
|
||||
best_frame = cv2.cvtColor(best_objects[obj_name]['frame'], cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
if ret:
|
||||
jpg_bytes = jpg.tobytes()
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}/snapshot", jpg_bytes, retain=True)
|
||||
|
||||
# expire any objects that are ON and no longer detected
|
||||
expired_objects = [obj_name for obj_name, status in current_object_status.items() if status == 'ON' and not obj_name in obj_counter]
|
||||
for obj_name in expired_objects:
|
||||
current_object_status[obj_name] = 'OFF'
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}", 'OFF', retain=False)
|
||||
# send updated snapshot over mqtt
|
||||
best_frame = cv2.cvtColor(best_objects[obj_name]['frame'], cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
if ret:
|
||||
jpg_bytes = jpg.tobytes()
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}/snapshot", jpg_bytes, retain=True)
|
||||
@@ -2,165 +2,95 @@ import time
|
||||
import datetime
|
||||
import threading
|
||||
import cv2
|
||||
import itertools
|
||||
import copy
|
||||
import numpy as np
|
||||
import random
|
||||
import string
|
||||
import multiprocessing as mp
|
||||
from collections import defaultdict
|
||||
from scipy.spatial import distance as dist
|
||||
from frigate.util import draw_box_with_label, calculate_region
|
||||
from object_detection.utils import visualization_utils as vis_util
|
||||
|
||||
class ObjectTracker():
|
||||
def __init__(self, max_disappeared):
|
||||
self.tracked_objects = {}
|
||||
self.disappeared = {}
|
||||
self.max_disappeared = max_disappeared
|
||||
class ObjectCleaner(threading.Thread):
|
||||
def __init__(self, objects_parsed, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self._objects_parsed = objects_parsed
|
||||
self._detected_objects = detected_objects
|
||||
|
||||
def register(self, index, obj):
|
||||
rand_id = ''.join(random.choices(string.ascii_lowercase + string.digits, k=6))
|
||||
id = f"{obj['frame_time']}-{rand_id}"
|
||||
obj['id'] = id
|
||||
obj['start_time'] = obj['frame_time']
|
||||
obj['top_score'] = obj['score']
|
||||
self.add_history(obj)
|
||||
self.tracked_objects[id] = obj
|
||||
self.disappeared[id] = 0
|
||||
def run(self):
|
||||
while True:
|
||||
|
||||
def deregister(self, id):
|
||||
del self.tracked_objects[id]
|
||||
del self.disappeared[id]
|
||||
|
||||
def update(self, id, new_obj):
|
||||
self.disappeared[id] = 0
|
||||
self.tracked_objects[id].update(new_obj)
|
||||
self.add_history(self.tracked_objects[id])
|
||||
if self.tracked_objects[id]['score'] > self.tracked_objects[id]['top_score']:
|
||||
self.tracked_objects[id]['top_score'] = self.tracked_objects[id]['score']
|
||||
|
||||
def add_history(self, obj):
|
||||
entry = {
|
||||
'score': obj['score'],
|
||||
'box': obj['box'],
|
||||
'region': obj['region'],
|
||||
'centroid': obj['centroid'],
|
||||
'frame_time': obj['frame_time']
|
||||
}
|
||||
if 'history' in obj:
|
||||
obj['history'].append(entry)
|
||||
# only maintain the last 20 in history
|
||||
if len(obj['history']) > 20:
|
||||
obj['history'] = obj['history'][-20:]
|
||||
else:
|
||||
obj['history'] = [entry]
|
||||
# wait a bit before checking for expired frames
|
||||
time.sleep(0.2)
|
||||
|
||||
def match_and_update(self, frame_time, new_objects):
|
||||
# group by name
|
||||
new_object_groups = defaultdict(lambda: [])
|
||||
for obj in new_objects:
|
||||
new_object_groups[obj[0]].append({
|
||||
'label': obj[0],
|
||||
'score': obj[1],
|
||||
'box': obj[2],
|
||||
'area': obj[3],
|
||||
'region': obj[4],
|
||||
'frame_time': frame_time
|
||||
})
|
||||
|
||||
# update any tracked objects with labels that are not
|
||||
# seen in the current objects and deregister if needed
|
||||
for obj in list(self.tracked_objects.values()):
|
||||
if not obj['label'] in new_object_groups:
|
||||
if self.disappeared[obj['id']] >= self.max_disappeared:
|
||||
self.deregister(obj['id'])
|
||||
else:
|
||||
self.disappeared[obj['id']] += 1
|
||||
|
||||
if len(new_objects) == 0:
|
||||
return
|
||||
|
||||
# track objects for each label type
|
||||
for label, group in new_object_groups.items():
|
||||
current_objects = [o for o in self.tracked_objects.values() if o['label'] == label]
|
||||
current_ids = [o['id'] for o in current_objects]
|
||||
current_centroids = np.array([o['centroid'] for o in current_objects])
|
||||
# expire the objects that are more than 1 second old
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# look for the first object found within the last second
|
||||
# (newest objects are appended to the end)
|
||||
detected_objects = self._detected_objects.copy()
|
||||
|
||||
# compute centroids of new objects
|
||||
for obj in group:
|
||||
centroid_x = int((obj['box'][0]+obj['box'][2]) / 2.0)
|
||||
centroid_y = int((obj['box'][1]+obj['box'][3]) / 2.0)
|
||||
obj['centroid'] = (centroid_x, centroid_y)
|
||||
num_to_delete = 0
|
||||
for obj in detected_objects:
|
||||
if now-obj['frame_time']<2:
|
||||
break
|
||||
num_to_delete += 1
|
||||
if num_to_delete > 0:
|
||||
del self._detected_objects[:num_to_delete]
|
||||
|
||||
if len(current_objects) == 0:
|
||||
for index, obj in enumerate(group):
|
||||
self.register(index, obj)
|
||||
return
|
||||
|
||||
new_centroids = np.array([o['centroid'] for o in group])
|
||||
# notify that parsed objects were changed
|
||||
with self._objects_parsed:
|
||||
self._objects_parsed.notify_all()
|
||||
|
||||
# compute the distance between each pair of tracked
|
||||
# centroids and new centroids, respectively -- our
|
||||
# goal will be to match each new centroid to an existing
|
||||
# object centroid
|
||||
D = dist.cdist(current_centroids, new_centroids)
|
||||
|
||||
# in order to perform this matching we must (1) find the
|
||||
# smallest value in each row and then (2) sort the row
|
||||
# indexes based on their minimum values so that the row
|
||||
# with the smallest value is at the *front* of the index
|
||||
# list
|
||||
rows = D.min(axis=1).argsort()
|
||||
# Maintains the frame and person with the highest score from the most recent
|
||||
# motion event
|
||||
class BestPersonFrame(threading.Thread):
|
||||
def __init__(self, objects_parsed, recent_frames, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self.objects_parsed = objects_parsed
|
||||
self.recent_frames = recent_frames
|
||||
self.detected_objects = detected_objects
|
||||
self.best_person = None
|
||||
self.best_frame = None
|
||||
|
||||
# next, we perform a similar process on the columns by
|
||||
# finding the smallest value in each column and then
|
||||
# sorting using the previously computed row index list
|
||||
cols = D.argmin(axis=1)[rows]
|
||||
def run(self):
|
||||
while True:
|
||||
|
||||
# in order to determine if we need to update, register,
|
||||
# or deregister an object we need to keep track of which
|
||||
# of the rows and column indexes we have already examined
|
||||
usedRows = set()
|
||||
usedCols = set()
|
||||
# wait until objects have been parsed
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.wait()
|
||||
|
||||
# loop over the combination of the (row, column) index
|
||||
# tuples
|
||||
for (row, col) in zip(rows, cols):
|
||||
# if we have already examined either the row or
|
||||
# column value before, ignore it
|
||||
if row in usedRows or col in usedCols:
|
||||
continue
|
||||
# make a copy of detected objects
|
||||
detected_objects = self.detected_objects.copy()
|
||||
detected_people = [obj for obj in detected_objects if obj['name'] == 'person']
|
||||
|
||||
# otherwise, grab the object ID for the current row,
|
||||
# set its new centroid, and reset the disappeared
|
||||
# counter
|
||||
objectID = current_ids[row]
|
||||
self.update(objectID, group[col])
|
||||
# get the highest scoring person
|
||||
new_best_person = max(detected_people, key=lambda x:x['score'], default=self.best_person)
|
||||
|
||||
# indicate that we have examined each of the row and
|
||||
# column indexes, respectively
|
||||
usedRows.add(row)
|
||||
usedCols.add(col)
|
||||
# if there isnt a person, continue
|
||||
if new_best_person is None:
|
||||
continue
|
||||
|
||||
# compute the column index we have NOT yet examined
|
||||
unusedRows = set(range(0, D.shape[0])).difference(usedRows)
|
||||
unusedCols = set(range(0, D.shape[1])).difference(usedCols)
|
||||
|
||||
# in the event that the number of object centroids is
|
||||
# equal or greater than the number of input centroids
|
||||
# we need to check and see if some of these objects have
|
||||
# potentially disappeared
|
||||
if D.shape[0] >= D.shape[1]:
|
||||
for row in unusedRows:
|
||||
id = current_ids[row]
|
||||
|
||||
if self.disappeared[id] >= self.max_disappeared:
|
||||
self.deregister(id)
|
||||
else:
|
||||
self.disappeared[id] += 1
|
||||
# if the number of input centroids is greater
|
||||
# than the number of existing object centroids we need to
|
||||
# register each new input centroid as a trackable object
|
||||
# if there is no current best_person
|
||||
if self.best_person is None:
|
||||
self.best_person = new_best_person
|
||||
# if there is already a best_person
|
||||
else:
|
||||
for col in unusedCols:
|
||||
self.register(col, group[col])
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# if the new best person is a higher score than the current best person
|
||||
# or the current person is more than 1 minute old, use the new best person
|
||||
if new_best_person['score'] > self.best_person['score'] or (now - self.best_person['frame_time']) > 60:
|
||||
self.best_person = new_best_person
|
||||
|
||||
# make a copy of the recent frames
|
||||
recent_frames = self.recent_frames.copy()
|
||||
|
||||
if not self.best_person is None and self.best_person['frame_time'] in recent_frames:
|
||||
best_frame = recent_frames[self.best_person['frame_time']]
|
||||
best_frame = cv2.cvtColor(best_frame, cv2.COLOR_BGR2RGB)
|
||||
# draw the bounding box on the frame
|
||||
vis_util.draw_bounding_box_on_image_array(best_frame,
|
||||
self.best_person['ymin'],
|
||||
self.best_person['xmin'],
|
||||
self.best_person['ymax'],
|
||||
self.best_person['xmax'],
|
||||
color='red',
|
||||
thickness=2,
|
||||
display_str_list=["{}: {}%".format(self.best_person['name'],int(self.best_person['score']*100))],
|
||||
use_normalized_coordinates=False)
|
||||
|
||||
# convert back to BGR
|
||||
self.best_frame = cv2.cvtColor(best_frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
193
frigate/util.py
Executable file → Normal file
193
frigate/util.py
Executable file → Normal file
@@ -1,192 +1,5 @@
|
||||
import datetime
|
||||
import time
|
||||
import signal
|
||||
import traceback
|
||||
import collections
|
||||
import numpy as np
|
||||
import cv2
|
||||
import threading
|
||||
import matplotlib.pyplot as plt
|
||||
import hashlib
|
||||
import pyarrow.plasma as plasma
|
||||
|
||||
def draw_box_with_label(frame, x_min, y_min, x_max, y_max, label, info, thickness=2, color=None, position='ul'):
|
||||
if color is None:
|
||||
color = (0,0,255)
|
||||
display_text = "{}: {}".format(label, info)
|
||||
cv2.rectangle(frame, (x_min, y_min), (x_max, y_max), color, thickness)
|
||||
font_scale = 0.5
|
||||
font = cv2.FONT_HERSHEY_SIMPLEX
|
||||
# get the width and height of the text box
|
||||
size = cv2.getTextSize(display_text, font, fontScale=font_scale, thickness=2)
|
||||
text_width = size[0][0]
|
||||
text_height = size[0][1]
|
||||
line_height = text_height + size[1]
|
||||
# set the text start position
|
||||
if position == 'ul':
|
||||
text_offset_x = x_min
|
||||
text_offset_y = 0 if y_min < line_height else y_min - (line_height+8)
|
||||
elif position == 'ur':
|
||||
text_offset_x = x_max - (text_width+8)
|
||||
text_offset_y = 0 if y_min < line_height else y_min - (line_height+8)
|
||||
elif position == 'bl':
|
||||
text_offset_x = x_min
|
||||
text_offset_y = y_max
|
||||
elif position == 'br':
|
||||
text_offset_x = x_max - (text_width+8)
|
||||
text_offset_y = y_max
|
||||
# make the coords of the box with a small padding of two pixels
|
||||
textbox_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y + line_height))
|
||||
cv2.rectangle(frame, textbox_coords[0], textbox_coords[1], color, cv2.FILLED)
|
||||
cv2.putText(frame, display_text, (text_offset_x, text_offset_y + line_height - 3), font, fontScale=font_scale, color=(0, 0, 0), thickness=2)
|
||||
|
||||
def calculate_region(frame_shape, xmin, ymin, xmax, ymax, multiplier=2):
|
||||
# size is larger than longest edge
|
||||
size = int(max(xmax-xmin, ymax-ymin)*multiplier)
|
||||
# if the size is too big to fit in the frame
|
||||
if size > min(frame_shape[0], frame_shape[1]):
|
||||
size = min(frame_shape[0], frame_shape[1])
|
||||
|
||||
# x_offset is midpoint of bounding box minus half the size
|
||||
x_offset = int((xmax-xmin)/2.0+xmin-size/2.0)
|
||||
# if outside the image
|
||||
if x_offset < 0:
|
||||
x_offset = 0
|
||||
elif x_offset > (frame_shape[1]-size):
|
||||
x_offset = (frame_shape[1]-size)
|
||||
|
||||
# y_offset is midpoint of bounding box minus half the size
|
||||
y_offset = int((ymax-ymin)/2.0+ymin-size/2.0)
|
||||
# if outside the image
|
||||
if y_offset < 0:
|
||||
y_offset = 0
|
||||
elif y_offset > (frame_shape[0]-size):
|
||||
y_offset = (frame_shape[0]-size)
|
||||
|
||||
return (x_offset, y_offset, x_offset+size, y_offset+size)
|
||||
|
||||
def intersection(box_a, box_b):
|
||||
return (
|
||||
max(box_a[0], box_b[0]),
|
||||
max(box_a[1], box_b[1]),
|
||||
min(box_a[2], box_b[2]),
|
||||
min(box_a[3], box_b[3])
|
||||
)
|
||||
|
||||
def area(box):
|
||||
return (box[2]-box[0] + 1)*(box[3]-box[1] + 1)
|
||||
|
||||
def intersection_over_union(box_a, box_b):
|
||||
# determine the (x, y)-coordinates of the intersection rectangle
|
||||
intersect = intersection(box_a, box_b)
|
||||
|
||||
# compute the area of intersection rectangle
|
||||
inter_area = max(0, intersect[2] - intersect[0] + 1) * max(0, intersect[3] - intersect[1] + 1)
|
||||
|
||||
if inter_area == 0:
|
||||
return 0.0
|
||||
|
||||
# compute the area of both the prediction and ground-truth
|
||||
# rectangles
|
||||
box_a_area = (box_a[2] - box_a[0] + 1) * (box_a[3] - box_a[1] + 1)
|
||||
box_b_area = (box_b[2] - box_b[0] + 1) * (box_b[3] - box_b[1] + 1)
|
||||
|
||||
# compute the intersection over union by taking the intersection
|
||||
# area and dividing it by the sum of prediction + ground-truth
|
||||
# areas - the interesection area
|
||||
iou = inter_area / float(box_a_area + box_b_area - inter_area)
|
||||
|
||||
# return the intersection over union value
|
||||
return iou
|
||||
|
||||
def clipped(obj, frame_shape):
|
||||
# if the object is within 5 pixels of the region border, and the region is not on the edge
|
||||
# consider the object to be clipped
|
||||
box = obj[2]
|
||||
region = obj[4]
|
||||
if ((region[0] > 5 and box[0]-region[0] <= 5) or
|
||||
(region[1] > 5 and box[1]-region[1] <= 5) or
|
||||
(frame_shape[1]-region[2] > 5 and region[2]-box[2] <= 5) or
|
||||
(frame_shape[0]-region[3] > 5 and region[3]-box[3] <= 5)):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
class EventsPerSecond:
|
||||
def __init__(self, max_events=1000):
|
||||
self._start = None
|
||||
self._max_events = max_events
|
||||
self._timestamps = []
|
||||
|
||||
def start(self):
|
||||
self._start = datetime.datetime.now().timestamp()
|
||||
|
||||
def update(self):
|
||||
self._timestamps.append(datetime.datetime.now().timestamp())
|
||||
# truncate the list when it goes 100 over the max_size
|
||||
if len(self._timestamps) > self._max_events+100:
|
||||
self._timestamps = self._timestamps[(1-self._max_events):]
|
||||
|
||||
def eps(self, last_n_seconds=10):
|
||||
# compute the (approximate) events in the last n seconds
|
||||
now = datetime.datetime.now().timestamp()
|
||||
seconds = min(now-self._start, last_n_seconds)
|
||||
return len([t for t in self._timestamps if t > (now-last_n_seconds)]) / seconds
|
||||
|
||||
def print_stack(sig, frame):
|
||||
traceback.print_stack(frame)
|
||||
|
||||
def listen():
|
||||
signal.signal(signal.SIGUSR1, print_stack)
|
||||
|
||||
class PlasmaManager:
|
||||
def __init__(self, stop_event=None):
|
||||
self.stop_event = stop_event
|
||||
self.connect()
|
||||
|
||||
def connect(self):
|
||||
while True:
|
||||
if self.stop_event != None and self.stop_event.is_set():
|
||||
return
|
||||
try:
|
||||
self.plasma_client = plasma.connect("/tmp/plasma")
|
||||
return
|
||||
except:
|
||||
print(f"TrackedObjectProcessor: unable to connect plasma client")
|
||||
time.sleep(10)
|
||||
|
||||
def get(self, name, timeout_ms=0):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
if self.stop_event != None and self.stop_event.is_set():
|
||||
return
|
||||
try:
|
||||
return self.plasma_client.get(object_id, timeout_ms=timeout_ms)
|
||||
except:
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
|
||||
def put(self, name, obj):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
if self.stop_event != None and self.stop_event.is_set():
|
||||
return
|
||||
try:
|
||||
self.plasma_client.put(obj, object_id)
|
||||
return
|
||||
except Exception as e:
|
||||
print(f"Failed to put in plasma: {e}")
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
|
||||
def delete(self, name):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
if self.stop_event != None and self.stop_event.is_set():
|
||||
return
|
||||
try:
|
||||
self.plasma_client.delete([object_id])
|
||||
return
|
||||
except:
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
# convert shared memory array into numpy array
|
||||
def tonumpyarray(mp_arr):
|
||||
return np.frombuffer(mp_arr.get_obj(), dtype=np.uint8)
|
||||
659
frigate/video.py
Executable file → Normal file
659
frigate/video.py
Executable file → Normal file
@@ -2,383 +2,328 @@ import os
|
||||
import time
|
||||
import datetime
|
||||
import cv2
|
||||
import queue
|
||||
import threading
|
||||
import ctypes
|
||||
import pyarrow.plasma as plasma
|
||||
import multiprocessing as mp
|
||||
import subprocess as sp
|
||||
import numpy as np
|
||||
import copy
|
||||
import itertools
|
||||
import json
|
||||
import base64
|
||||
from collections import defaultdict
|
||||
from frigate.util import draw_box_with_label, area, calculate_region, clipped, intersection_over_union, intersection, EventsPerSecond, listen, PlasmaManager
|
||||
from frigate.objects import ObjectTracker
|
||||
from frigate.edgetpu import RemoteObjectDetector
|
||||
from frigate.motion import MotionDetector
|
||||
from object_detection.utils import visualization_utils as vis_util
|
||||
from . util import tonumpyarray
|
||||
from . object_detection import FramePrepper
|
||||
from . objects import ObjectCleaner, BestPersonFrame
|
||||
from . mqtt import MqttObjectPublisher
|
||||
|
||||
def get_frame_shape(source):
|
||||
ffprobe_cmd = " ".join([
|
||||
'ffprobe',
|
||||
'-v',
|
||||
'panic',
|
||||
'-show_error',
|
||||
'-show_streams',
|
||||
'-of',
|
||||
'json',
|
||||
'"'+source+'"'
|
||||
])
|
||||
print(ffprobe_cmd)
|
||||
p = sp.Popen(ffprobe_cmd, stdout=sp.PIPE, shell=True)
|
||||
(output, err) = p.communicate()
|
||||
p_status = p.wait()
|
||||
info = json.loads(output)
|
||||
print(info)
|
||||
# fetch the frames as fast a possible and store current frame in a shared memory array
|
||||
def fetch_frames(shared_arr, shared_frame_time, frame_lock, frame_ready, frame_shape, rtsp_url, take_frame=1):
|
||||
# convert shared memory array into numpy and shape into image array
|
||||
arr = tonumpyarray(shared_arr).reshape(frame_shape)
|
||||
|
||||
video_info = [s for s in info['streams'] if s['codec_type'] == 'video'][0]
|
||||
# start the video capture
|
||||
video = cv2.VideoCapture()
|
||||
video.open(rtsp_url)
|
||||
# keep the buffer small so we minimize old data
|
||||
video.set(cv2.CAP_PROP_BUFFERSIZE,1)
|
||||
|
||||
if video_info['height'] != 0 and video_info['width'] != 0:
|
||||
return (video_info['height'], video_info['width'], 3)
|
||||
bad_frame_counter = 0
|
||||
frame_num = 0
|
||||
while True:
|
||||
# check if the video stream is still open, and reopen if needed
|
||||
if not video.isOpened():
|
||||
success = video.open(rtsp_url)
|
||||
if not success:
|
||||
time.sleep(1)
|
||||
continue
|
||||
# grab the frame, but dont decode it yet
|
||||
ret = video.grab()
|
||||
# snapshot the time the frame was grabbed
|
||||
frame_time = datetime.datetime.now()
|
||||
if ret:
|
||||
frame_num += 1
|
||||
if (frame_num % take_frame) != 0:
|
||||
continue
|
||||
# go ahead and decode the current frame
|
||||
ret, frame = video.retrieve()
|
||||
if ret:
|
||||
# Lock access and update frame
|
||||
with frame_lock:
|
||||
arr[:] = frame
|
||||
shared_frame_time.value = frame_time.timestamp()
|
||||
# Notify with the condition that a new frame is ready
|
||||
with frame_ready:
|
||||
frame_ready.notify_all()
|
||||
bad_frame_counter = 0
|
||||
else:
|
||||
print("Unable to decode frame")
|
||||
bad_frame_counter += 1
|
||||
else:
|
||||
print("Unable to grab a frame")
|
||||
bad_frame_counter += 1
|
||||
|
||||
if bad_frame_counter > 100:
|
||||
video.release()
|
||||
|
||||
# fallback to using opencv if ffprobe didnt succeed
|
||||
video = cv2.VideoCapture(source)
|
||||
video.release()
|
||||
|
||||
# Stores 2 seconds worth of frames when motion is detected so they can be used for other threads
|
||||
class FrameTracker(threading.Thread):
|
||||
def __init__(self, shared_frame, frame_time, frame_ready, frame_lock, recent_frames):
|
||||
threading.Thread.__init__(self)
|
||||
self.shared_frame = shared_frame
|
||||
self.frame_time = frame_time
|
||||
self.frame_ready = frame_ready
|
||||
self.frame_lock = frame_lock
|
||||
self.recent_frames = recent_frames
|
||||
|
||||
def run(self):
|
||||
frame_time = 0.0
|
||||
while True:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# wait for a frame
|
||||
with self.frame_ready:
|
||||
# if there isnt a frame ready for processing or it is old, wait for a signal
|
||||
if self.frame_time.value == frame_time or (now - self.frame_time.value) > 0.5:
|
||||
self.frame_ready.wait()
|
||||
|
||||
# lock and make a copy of the frame
|
||||
with self.frame_lock:
|
||||
frame = self.shared_frame.copy()
|
||||
frame_time = self.frame_time.value
|
||||
|
||||
# add the frame to recent frames
|
||||
self.recent_frames[frame_time] = frame
|
||||
|
||||
# delete any old frames
|
||||
stored_frame_times = list(self.recent_frames.keys())
|
||||
for k in stored_frame_times:
|
||||
if (now - k) > 2:
|
||||
del self.recent_frames[k]
|
||||
|
||||
def get_frame_shape(rtsp_url):
|
||||
# capture a single frame and check the frame shape so the correct array
|
||||
# size can be allocated in memory
|
||||
video = cv2.VideoCapture(rtsp_url)
|
||||
ret, frame = video.read()
|
||||
frame_shape = frame.shape
|
||||
video.release()
|
||||
return frame_shape
|
||||
|
||||
def get_ffmpeg_input(ffmpeg_input):
|
||||
frigate_vars = {k: v for k, v in os.environ.items() if k.startswith('FRIGATE_')}
|
||||
return ffmpeg_input.format(**frigate_vars)
|
||||
def get_rtsp_url(rtsp_config):
|
||||
if (rtsp_config['password'].startswith('$')):
|
||||
rtsp_config['password'] = os.getenv(rtsp_config['password'][1:])
|
||||
return 'rtsp://{}:{}@{}:{}{}'.format(rtsp_config['user'],
|
||||
rtsp_config['password'], rtsp_config['host'], rtsp_config['port'],
|
||||
rtsp_config['path'])
|
||||
|
||||
def filtered(obj, objects_to_track, object_filters, mask):
|
||||
object_name = obj[0]
|
||||
def compute_sizes(frame_shape, known_sizes, mask):
|
||||
# create a 3 dimensional numpy array to store estimated sizes
|
||||
estimated_sizes = np.zeros((frame_shape[0], frame_shape[1], 2), np.uint32)
|
||||
|
||||
if not object_name in objects_to_track:
|
||||
return True
|
||||
|
||||
if object_name in object_filters:
|
||||
obj_settings = object_filters[object_name]
|
||||
sorted_positions = sorted(known_sizes, key=lambda s: s['y'])
|
||||
|
||||
# if the min area is larger than the
|
||||
# detected object, don't add it to detected objects
|
||||
if obj_settings.get('min_area',-1) > obj[3]:
|
||||
return True
|
||||
|
||||
# if the detected object is larger than the
|
||||
# max area, don't add it to detected objects
|
||||
if obj_settings.get('max_area', 24000000) < obj[3]:
|
||||
return True
|
||||
last_position = {'y': 0, 'min': 0, 'max': 0}
|
||||
next_position = sorted_positions.pop(0)
|
||||
# if the next position has the same y coordinate, skip
|
||||
while next_position['y'] == last_position['y']:
|
||||
next_position = sorted_positions.pop(0)
|
||||
y_change = next_position['y']-last_position['y']
|
||||
min_size_change = next_position['min']-last_position['min']
|
||||
max_size_change = next_position['max']-last_position['max']
|
||||
min_step_size = min_size_change/y_change
|
||||
max_step_size = max_size_change/y_change
|
||||
|
||||
# if the score is lower than the threshold, skip
|
||||
if obj_settings.get('threshold', 0) > obj[1]:
|
||||
return True
|
||||
|
||||
# compute the coordinates of the object and make sure
|
||||
# the location isnt outside the bounds of the image (can happen from rounding)
|
||||
y_location = min(int(obj[2][3]), len(mask)-1)
|
||||
x_location = min(int((obj[2][2]-obj[2][0])/2.0)+obj[2][0], len(mask[0])-1)
|
||||
min_current_size = 0
|
||||
max_current_size = 0
|
||||
|
||||
# if the object is in a masked location, don't add it to detected objects
|
||||
if mask[y_location][x_location] == [0]:
|
||||
return True
|
||||
|
||||
return False
|
||||
for y_position in range(frame_shape[0]):
|
||||
# fill the row with the estimated size
|
||||
estimated_sizes[y_position,:] = [min_current_size, max_current_size]
|
||||
|
||||
def create_tensor_input(frame, region):
|
||||
cropped_frame = frame[region[1]:region[3], region[0]:region[2]]
|
||||
|
||||
# Resize to 300x300 if needed
|
||||
if cropped_frame.shape != (300, 300, 3):
|
||||
cropped_frame = cv2.resize(cropped_frame, dsize=(300, 300), interpolation=cv2.INTER_LINEAR)
|
||||
|
||||
# Expand dimensions since the model expects images to have shape: [1, 300, 300, 3]
|
||||
return np.expand_dims(cropped_frame, axis=0)
|
||||
|
||||
def start_or_restart_ffmpeg(ffmpeg_cmd, frame_size, ffmpeg_process=None):
|
||||
if not ffmpeg_process is None:
|
||||
print("Terminating the existing ffmpeg process...")
|
||||
ffmpeg_process.terminate()
|
||||
try:
|
||||
print("Waiting for ffmpeg to exit gracefully...")
|
||||
ffmpeg_process.communicate(timeout=30)
|
||||
except sp.TimeoutExpired:
|
||||
print("FFmpeg didnt exit. Force killing...")
|
||||
ffmpeg_process.kill()
|
||||
ffmpeg_process.communicate()
|
||||
ffmpeg_process = None
|
||||
|
||||
print("Creating ffmpeg process...")
|
||||
print(" ".join(ffmpeg_cmd))
|
||||
process = sp.Popen(ffmpeg_cmd, stdout = sp.PIPE, stdin = sp.DEVNULL, bufsize=frame_size*10, start_new_session=True)
|
||||
return process
|
||||
|
||||
class CameraCapture(threading.Thread):
|
||||
def __init__(self, name, ffmpeg_process, frame_shape, frame_queue, take_frame, fps, detection_frame, stop_event):
|
||||
threading.Thread.__init__(self)
|
||||
self.name = name
|
||||
self.frame_shape = frame_shape
|
||||
self.frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
self.frame_queue = frame_queue
|
||||
self.take_frame = take_frame
|
||||
self.fps = fps
|
||||
self.skipped_fps = EventsPerSecond()
|
||||
self.plasma_client = PlasmaManager(stop_event)
|
||||
self.ffmpeg_process = ffmpeg_process
|
||||
self.current_frame = 0
|
||||
self.last_frame = 0
|
||||
self.detection_frame = detection_frame
|
||||
self.stop_event = stop_event
|
||||
|
||||
def run(self):
|
||||
frame_num = 0
|
||||
self.skipped_fps.start()
|
||||
while True:
|
||||
if self.stop_event.is_set():
|
||||
print(f"{self.name}: stop event set. exiting capture thread...")
|
||||
break
|
||||
|
||||
if self.ffmpeg_process.poll() != None:
|
||||
print(f"{self.name}: ffmpeg process is not running. exiting capture thread...")
|
||||
break
|
||||
|
||||
frame_bytes = self.ffmpeg_process.stdout.read(self.frame_size)
|
||||
self.current_frame = datetime.datetime.now().timestamp()
|
||||
|
||||
if len(frame_bytes) == 0:
|
||||
print(f"{self.name}: ffmpeg didnt return a frame. something is wrong.")
|
||||
continue
|
||||
|
||||
self.fps.update()
|
||||
|
||||
frame_num += 1
|
||||
if (frame_num % self.take_frame) != 0:
|
||||
self.skipped_fps.update()
|
||||
continue
|
||||
|
||||
# if the detection process is more than 1 second behind, skip this frame
|
||||
if self.detection_frame.value > 0.0 and (self.last_frame - self.detection_frame.value) > 1:
|
||||
self.skipped_fps.update()
|
||||
continue
|
||||
|
||||
# put the frame in the plasma store
|
||||
self.plasma_client.put(f"{self.name}{self.current_frame}",
|
||||
np
|
||||
.frombuffer(frame_bytes, np.uint8)
|
||||
.reshape(self.frame_shape)
|
||||
)
|
||||
# add to the queue
|
||||
self.frame_queue.put(self.current_frame)
|
||||
self.last_frame = self.current_frame
|
||||
|
||||
def track_camera(name, config, global_objects_config, frame_queue, frame_shape, detection_queue, detected_objects_queue, fps, detection_fps, read_start, detection_frame):
|
||||
print(f"Starting process for {name}: {os.getpid()}")
|
||||
listen()
|
||||
|
||||
detection_frame.value = 0.0
|
||||
|
||||
# Merge the tracked object config with the global config
|
||||
camera_objects_config = config.get('objects', {})
|
||||
# combine tracked objects lists
|
||||
objects_to_track = set().union(global_objects_config.get('track', ['person', 'car', 'truck']), camera_objects_config.get('track', []))
|
||||
# merge object filters
|
||||
global_object_filters = global_objects_config.get('filters', {})
|
||||
camera_object_filters = camera_objects_config.get('filters', {})
|
||||
objects_with_config = set().union(global_object_filters.keys(), camera_object_filters.keys())
|
||||
object_filters = {}
|
||||
for obj in objects_with_config:
|
||||
object_filters[obj] = {**global_object_filters.get(obj, {}), **camera_object_filters.get(obj, {})}
|
||||
|
||||
frame = np.zeros(frame_shape, np.uint8)
|
||||
|
||||
# load in the mask for object detection
|
||||
if 'mask' in config:
|
||||
if config['mask'].startswith('base64,'):
|
||||
img = base64.b64decode(config['mask'][7:])
|
||||
npimg = np.fromstring(img, dtype=np.uint8)
|
||||
mask = cv2.imdecode(npimg, cv2.IMREAD_GRAYSCALE)
|
||||
else:
|
||||
mask = cv2.imread("/config/{}".format(config['mask']), cv2.IMREAD_GRAYSCALE)
|
||||
else:
|
||||
mask = None
|
||||
|
||||
if mask is None:
|
||||
mask = np.zeros((frame_shape[0], frame_shape[1], 1), np.uint8)
|
||||
mask[:] = 255
|
||||
|
||||
motion_detector = MotionDetector(frame_shape, mask, resize_factor=6)
|
||||
object_detector = RemoteObjectDetector(name, '/labelmap.txt', detection_queue)
|
||||
|
||||
object_tracker = ObjectTracker(10)
|
||||
|
||||
plasma_client = PlasmaManager()
|
||||
avg_wait = 0.0
|
||||
fps_tracker = EventsPerSecond()
|
||||
fps_tracker.start()
|
||||
object_detector.fps.start()
|
||||
while True:
|
||||
read_start.value = datetime.datetime.now().timestamp()
|
||||
frame_time = frame_queue.get()
|
||||
duration = datetime.datetime.now().timestamp()-read_start.value
|
||||
read_start.value = 0.0
|
||||
avg_wait = (avg_wait*99+duration)/100
|
||||
detection_frame.value = frame_time
|
||||
|
||||
# Get frame from plasma store
|
||||
frame = plasma_client.get(f"{name}{frame_time}")
|
||||
|
||||
if frame is plasma.ObjectNotAvailable:
|
||||
continue
|
||||
|
||||
fps_tracker.update()
|
||||
fps.value = fps_tracker.eps()
|
||||
detection_fps.value = object_detector.fps.eps()
|
||||
|
||||
# look for motion
|
||||
motion_boxes = motion_detector.detect(frame)
|
||||
|
||||
tracked_objects = object_tracker.tracked_objects.values()
|
||||
|
||||
# merge areas of motion that intersect with a known tracked object into a single area to look at
|
||||
areas_of_interest = []
|
||||
used_motion_boxes = []
|
||||
for obj in tracked_objects:
|
||||
x_min, y_min, x_max, y_max = obj['box']
|
||||
for m_index, motion_box in enumerate(motion_boxes):
|
||||
if intersection_over_union(motion_box, obj['box']) > .2:
|
||||
used_motion_boxes.append(m_index)
|
||||
x_min = min(obj['box'][0], motion_box[0])
|
||||
y_min = min(obj['box'][1], motion_box[1])
|
||||
x_max = max(obj['box'][2], motion_box[2])
|
||||
y_max = max(obj['box'][3], motion_box[3])
|
||||
areas_of_interest.append((x_min, y_min, x_max, y_max))
|
||||
unused_motion_boxes = set(range(0, len(motion_boxes))).difference(used_motion_boxes)
|
||||
|
||||
# compute motion regions
|
||||
motion_regions = [calculate_region(frame_shape, motion_boxes[i][0], motion_boxes[i][1], motion_boxes[i][2], motion_boxes[i][3], 1.2)
|
||||
for i in unused_motion_boxes]
|
||||
|
||||
# compute tracked object regions
|
||||
object_regions = [calculate_region(frame_shape, a[0], a[1], a[2], a[3], 1.2)
|
||||
for a in areas_of_interest]
|
||||
|
||||
# merge regions with high IOU
|
||||
merged_regions = motion_regions+object_regions
|
||||
while True:
|
||||
max_iou = 0.0
|
||||
max_indices = None
|
||||
region_indices = range(len(merged_regions))
|
||||
for a, b in itertools.combinations(region_indices, 2):
|
||||
iou = intersection_over_union(merged_regions[a], merged_regions[b])
|
||||
if iou > max_iou:
|
||||
max_iou = iou
|
||||
max_indices = (a, b)
|
||||
if max_iou > 0.1:
|
||||
a = merged_regions[max_indices[0]]
|
||||
b = merged_regions[max_indices[1]]
|
||||
merged_regions.append(calculate_region(frame_shape,
|
||||
min(a[0], b[0]),
|
||||
min(a[1], b[1]),
|
||||
max(a[2], b[2]),
|
||||
max(a[3], b[3]),
|
||||
1
|
||||
))
|
||||
del merged_regions[max(max_indices[0], max_indices[1])]
|
||||
del merged_regions[min(max_indices[0], max_indices[1])]
|
||||
# if you have reached the next size
|
||||
if y_position == next_position['y']:
|
||||
last_position = next_position
|
||||
# if there are still positions left
|
||||
if len(sorted_positions) > 0:
|
||||
next_position = sorted_positions.pop(0)
|
||||
# if the next position has the same y coordinate, skip
|
||||
while next_position['y'] == last_position['y']:
|
||||
next_position = sorted_positions.pop(0)
|
||||
y_change = next_position['y']-last_position['y']
|
||||
min_size_change = next_position['min']-last_position['min']
|
||||
max_size_change = next_position['max']-last_position['max']
|
||||
min_step_size = min_size_change/y_change
|
||||
max_step_size = max_size_change/y_change
|
||||
else:
|
||||
break
|
||||
|
||||
# resize regions and detect
|
||||
detections = []
|
||||
for region in merged_regions:
|
||||
|
||||
tensor_input = create_tensor_input(frame, region)
|
||||
|
||||
region_detections = object_detector.detect(tensor_input)
|
||||
|
||||
for d in region_detections:
|
||||
box = d[2]
|
||||
size = region[2]-region[0]
|
||||
x_min = int((box[1] * size) + region[0])
|
||||
y_min = int((box[0] * size) + region[1])
|
||||
x_max = int((box[3] * size) + region[0])
|
||||
y_max = int((box[2] * size) + region[1])
|
||||
det = (d[0],
|
||||
d[1],
|
||||
(x_min, y_min, x_max, y_max),
|
||||
(x_max-x_min)*(y_max-y_min),
|
||||
region)
|
||||
if filtered(det, objects_to_track, object_filters, mask):
|
||||
continue
|
||||
detections.append(det)
|
||||
|
||||
#########
|
||||
# merge objects, check for clipped objects and look again up to N times
|
||||
#########
|
||||
refining = True
|
||||
refine_count = 0
|
||||
while refining and refine_count < 4:
|
||||
refining = False
|
||||
|
||||
# group by name
|
||||
detected_object_groups = defaultdict(lambda: [])
|
||||
for detection in detections:
|
||||
detected_object_groups[detection[0]].append(detection)
|
||||
|
||||
selected_objects = []
|
||||
for group in detected_object_groups.values():
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping bounding boxes
|
||||
boxes = [(o[2][0], o[2][1], o[2][2]-o[2][0], o[2][3]-o[2][1])
|
||||
for o in group]
|
||||
confidences = [o[1] for o in group]
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
|
||||
|
||||
for index in idxs:
|
||||
obj = group[index[0]]
|
||||
if clipped(obj, frame_shape):
|
||||
box = obj[2]
|
||||
# calculate a new region that will hopefully get the entire object
|
||||
region = calculate_region(frame_shape,
|
||||
box[0], box[1],
|
||||
box[2], box[3])
|
||||
|
||||
tensor_input = create_tensor_input(frame, region)
|
||||
# run detection on new region
|
||||
refined_detections = object_detector.detect(tensor_input)
|
||||
for d in refined_detections:
|
||||
box = d[2]
|
||||
size = region[2]-region[0]
|
||||
x_min = int((box[1] * size) + region[0])
|
||||
y_min = int((box[0] * size) + region[1])
|
||||
x_max = int((box[3] * size) + region[0])
|
||||
y_max = int((box[2] * size) + region[1])
|
||||
det = (d[0],
|
||||
d[1],
|
||||
(x_min, y_min, x_max, y_max),
|
||||
(x_max-x_min)*(y_max-y_min),
|
||||
region)
|
||||
if filtered(det, objects_to_track, object_filters, mask):
|
||||
continue
|
||||
selected_objects.append(det)
|
||||
|
||||
refining = True
|
||||
else:
|
||||
selected_objects.append(obj)
|
||||
|
||||
# set the detections list to only include top, complete objects
|
||||
# and new detections
|
||||
detections = selected_objects
|
||||
|
||||
if refining:
|
||||
refine_count += 1
|
||||
min_step_size = 0
|
||||
max_step_size = 0
|
||||
|
||||
# now that we have refined our detections, we need to track objects
|
||||
object_tracker.match_and_update(frame_time, detections)
|
||||
min_current_size += min_step_size
|
||||
max_current_size += max_step_size
|
||||
|
||||
# add to the queue
|
||||
detected_objects_queue.put((name, frame_time, object_tracker.tracked_objects))
|
||||
# apply mask by filling 0s for all locations a person could not be standing
|
||||
if mask is not None:
|
||||
pass
|
||||
|
||||
print(f"{name}: exiting subprocess")
|
||||
return estimated_sizes
|
||||
|
||||
class Camera:
|
||||
def __init__(self, name, config, prepped_frame_queue, mqtt_client, mqtt_prefix, debug=False):
|
||||
self.name = name
|
||||
self.config = config
|
||||
self.detected_objects = []
|
||||
self.recent_frames = {}
|
||||
self.rtsp_url = get_rtsp_url(self.config['rtsp'])
|
||||
self.take_frame = self.config.get('take_frame', 1)
|
||||
self.regions = self.config['regions']
|
||||
self.frame_shape = get_frame_shape(self.rtsp_url)
|
||||
self.mqtt_client = mqtt_client
|
||||
self.mqtt_topic_prefix = '{}/{}'.format(mqtt_prefix, self.name)
|
||||
self.debug = debug
|
||||
|
||||
# compute the flattened array length from the shape of the frame
|
||||
flat_array_length = self.frame_shape[0] * self.frame_shape[1] * self.frame_shape[2]
|
||||
# create shared array for storing the full frame image data
|
||||
self.shared_frame_array = mp.Array(ctypes.c_uint8, flat_array_length)
|
||||
# create shared value for storing the frame_time
|
||||
self.shared_frame_time = mp.Value('d', 0.0)
|
||||
# Lock to control access to the frame
|
||||
self.frame_lock = mp.Lock()
|
||||
# Condition for notifying that a new frame is ready
|
||||
self.frame_ready = mp.Condition()
|
||||
# Condition for notifying that objects were parsed
|
||||
self.objects_parsed = mp.Condition()
|
||||
|
||||
# shape current frame so it can be treated as a numpy image
|
||||
self.shared_frame_np = tonumpyarray(self.shared_frame_array).reshape(self.frame_shape)
|
||||
|
||||
# create the process to capture frames from the RTSP stream and store in a shared array
|
||||
self.capture_process = mp.Process(target=fetch_frames, args=(self.shared_frame_array,
|
||||
self.shared_frame_time, self.frame_lock, self.frame_ready, self.frame_shape,
|
||||
self.rtsp_url, self.take_frame))
|
||||
self.capture_process.daemon = True
|
||||
|
||||
# for each region, create a separate thread to resize the region and prep for detection
|
||||
self.detection_prep_threads = []
|
||||
for region in self.config['regions']:
|
||||
self.detection_prep_threads.append(FramePrepper(
|
||||
self.name,
|
||||
self.shared_frame_np,
|
||||
self.shared_frame_time,
|
||||
self.frame_ready,
|
||||
self.frame_lock,
|
||||
region['size'], region['x_offset'], region['y_offset'],
|
||||
prepped_frame_queue
|
||||
))
|
||||
|
||||
# start a thread to store recent motion frames for processing
|
||||
self.frame_tracker = FrameTracker(self.shared_frame_np, self.shared_frame_time,
|
||||
self.frame_ready, self.frame_lock, self.recent_frames)
|
||||
self.frame_tracker.start()
|
||||
|
||||
# start a thread to store the highest scoring recent person frame
|
||||
self.best_person_frame = BestPersonFrame(self.objects_parsed, self.recent_frames, self.detected_objects)
|
||||
self.best_person_frame.start()
|
||||
|
||||
# start a thread to expire objects from the detected objects list
|
||||
self.object_cleaner = ObjectCleaner(self.objects_parsed, self.detected_objects)
|
||||
self.object_cleaner.start()
|
||||
|
||||
# start a thread to publish object scores (currently only person)
|
||||
mqtt_publisher = MqttObjectPublisher(self.mqtt_client, self.mqtt_topic_prefix, self.objects_parsed, self.detected_objects)
|
||||
mqtt_publisher.start()
|
||||
|
||||
# load in the mask for person detection
|
||||
if 'mask' in self.config:
|
||||
self.mask = cv2.imread("/config/{}".format(self.config['mask']), cv2.IMREAD_GRAYSCALE)
|
||||
else:
|
||||
self.mask = np.zeros((self.frame_shape[0], self.frame_shape[1], 1), np.uint8)
|
||||
self.mask[:] = 255
|
||||
|
||||
# pre-compute estimated person size for every pixel in the image
|
||||
if 'known_sizes' in self.config:
|
||||
self.calculated_person_sizes = compute_sizes((self.frame_shape[0], self.frame_shape[1]),
|
||||
self.config['known_sizes'], None)
|
||||
else:
|
||||
self.calculated_person_sizes = None
|
||||
|
||||
def start(self):
|
||||
self.capture_process.start()
|
||||
# start the object detection prep threads
|
||||
for detection_prep_thread in self.detection_prep_threads:
|
||||
detection_prep_thread.start()
|
||||
|
||||
def join(self):
|
||||
self.capture_process.join()
|
||||
|
||||
def get_capture_pid(self):
|
||||
return self.capture_process.pid
|
||||
|
||||
def add_objects(self, objects):
|
||||
if len(objects) == 0:
|
||||
return
|
||||
|
||||
for obj in objects:
|
||||
if self.debug:
|
||||
# print out the detected objects, scores and locations
|
||||
print(self.name, obj['name'], obj['score'], obj['xmin'], obj['ymin'], obj['xmax'], obj['ymax'])
|
||||
|
||||
location = (int(obj['ymax']), int((obj['xmax']-obj['xmin'])/2))
|
||||
|
||||
# if the person is in a masked location, continue
|
||||
if self.mask[location[0]][location[1]] == [0]:
|
||||
continue
|
||||
|
||||
if self.calculated_person_sizes is not None and obj['name'] == 'person':
|
||||
person_size_range = self.calculated_person_sizes[location[0]][location[1]]
|
||||
|
||||
# if the person isnt on the ground, continue
|
||||
if(person_size_range[0] == 0 and person_size_range[1] == 0):
|
||||
continue
|
||||
|
||||
person_size = (obj['xmax']-obj['xmin'])*(obj['ymax']-obj['ymin'])
|
||||
|
||||
# if the person is not within 20% of the estimated size for that location, continue
|
||||
if person_size < person_size_range[0] or person_size > person_size_range[1]:
|
||||
continue
|
||||
|
||||
self.detected_objects.append(obj)
|
||||
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.notify_all()
|
||||
|
||||
def get_best_person(self):
|
||||
return self.best_person_frame.best_frame
|
||||
|
||||
def get_current_frame_with_objects(self):
|
||||
# make a copy of the current detected objects
|
||||
detected_objects = self.detected_objects.copy()
|
||||
# lock and make a copy of the current frame
|
||||
with self.frame_lock:
|
||||
frame = self.shared_frame_np.copy()
|
||||
|
||||
# convert to RGB for drawing
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
|
||||
# draw the bounding boxes on the screen
|
||||
for obj in detected_objects:
|
||||
vis_util.draw_bounding_box_on_image_array(frame,
|
||||
obj['ymin'],
|
||||
obj['xmin'],
|
||||
obj['ymax'],
|
||||
obj['xmax'],
|
||||
color='red',
|
||||
thickness=2,
|
||||
display_str_list=["{}: {}%".format(obj['name'],int(obj['score']*100))],
|
||||
use_normalized_coordinates=False)
|
||||
|
||||
for region in self.regions:
|
||||
color = (255,255,255)
|
||||
cv2.rectangle(frame, (region['x_offset'], region['y_offset']),
|
||||
(region['x_offset']+region['size'], region['y_offset']+region['size']),
|
||||
color, 2)
|
||||
|
||||
# convert back to BGR
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
return frame
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user