forked from Github/frigate
Compare commits
1 Commits
v0.5.1-rc2
...
odroid
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
228d5ed9c1 |
@@ -1,6 +1 @@
|
||||
README.md
|
||||
diagram.png
|
||||
.gitignore
|
||||
debug
|
||||
config/
|
||||
*.pyc
|
||||
1
.github/FUNDING.yml
vendored
1
.github/FUNDING.yml
vendored
@@ -1 +0,0 @@
|
||||
github: blakeblackshear
|
||||
2
.gitignore
vendored
2
.gitignore
vendored
@@ -1,4 +1,2 @@
|
||||
*.pyc
|
||||
debug
|
||||
.vscode
|
||||
config/config.yml
|
||||
130
Dockerfile
Executable file → Normal file
130
Dockerfile
Executable file → Normal file
@@ -1,59 +1,97 @@
|
||||
FROM ubuntu:18.04
|
||||
LABEL maintainer "blakeb@blakeshome.com"
|
||||
|
||||
ENV DEBIAN_FRONTEND=noninteractive
|
||||
# Install packages for apt repo
|
||||
RUN apt -qq update && apt -qq install --no-install-recommends -y \
|
||||
software-properties-common \
|
||||
# apt-transport-https ca-certificates \
|
||||
build-essential \
|
||||
gnupg wget unzip \
|
||||
# libcap-dev \
|
||||
&& add-apt-repository ppa:deadsnakes/ppa -y \
|
||||
&& apt -qq install --no-install-recommends -y \
|
||||
python3.7 \
|
||||
python3.7-dev \
|
||||
python3-pip \
|
||||
RUN apt-get -qq update && apt-get -qq install --no-install-recommends -y \
|
||||
apt-transport-https \
|
||||
ca-certificates \
|
||||
curl \
|
||||
wget \
|
||||
gnupg-agent \
|
||||
dirmngr \
|
||||
software-properties-common
|
||||
|
||||
RUN apt-key adv --keyserver keyserver.ubuntu.com --recv-keys D986B59D
|
||||
|
||||
RUN echo "deb http://deb.odroid.in/5422-s bionic main" > /etc/apt/sources.list.d/odroid.list
|
||||
|
||||
RUN apt-get -qq update && apt-get -qq install --no-install-recommends -y \
|
||||
python3 \
|
||||
# OpenCV dependencies
|
||||
ffmpeg \
|
||||
# VAAPI drivers for Intel hardware accel
|
||||
libva-drm2 libva2 i965-va-driver vainfo \
|
||||
&& python3.7 -m pip install -U wheel setuptools \
|
||||
&& python3.7 -m pip install -U \
|
||||
opencv-python-headless \
|
||||
# python-prctl \
|
||||
build-essential \
|
||||
cmake \
|
||||
unzip \
|
||||
pkg-config \
|
||||
libjpeg-dev \
|
||||
libpng-dev \
|
||||
libtiff-dev \
|
||||
libavcodec-dev \
|
||||
libavformat-dev \
|
||||
libswscale-dev \
|
||||
libv4l-dev \
|
||||
libxvidcore-dev \
|
||||
libx264-dev \
|
||||
libgtk-3-dev \
|
||||
libatlas-base-dev \
|
||||
gfortran \
|
||||
python3-dev \
|
||||
# Coral USB Python API Dependencies
|
||||
libusb-1.0-0 \
|
||||
python3-pip \
|
||||
python3-pil \
|
||||
python3-numpy \
|
||||
libc++1 \
|
||||
libc++abi1 \
|
||||
libunwind8 \
|
||||
libgcc1 \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
# Install core packages
|
||||
RUN wget -q -O /tmp/get-pip.py --no-check-certificate https://bootstrap.pypa.io/get-pip.py && python3 /tmp/get-pip.py
|
||||
RUN pip install -U pip \
|
||||
numpy \
|
||||
imutils \
|
||||
scipy \
|
||||
&& python3.7 -m pip install -U \
|
||||
Flask \
|
||||
paho-mqtt \
|
||||
PyYAML \
|
||||
matplotlib \
|
||||
pyarrow \
|
||||
&& echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" > /etc/apt/sources.list.d/coral-edgetpu.list \
|
||||
&& wget -q -O - https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - \
|
||||
&& apt -qq update \
|
||||
&& echo "libedgetpu1-max libedgetpu/accepted-eula boolean true" | debconf-set-selections \
|
||||
&& apt -qq install --no-install-recommends -y \
|
||||
libedgetpu1-max \
|
||||
## Tensorflow lite (python 3.7 only)
|
||||
&& wget -q https://dl.google.com/coral/python/tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& python3.7 -m pip install tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& rm tflite_runtime-2.1.0.post1-cp37-cp37m-linux_x86_64.whl \
|
||||
&& rm -rf /var/lib/apt/lists/* \
|
||||
&& (apt-get autoremove -y; apt-get autoclean -y)
|
||||
PyYAML
|
||||
|
||||
# get model and labels
|
||||
RUN wget -q https://github.com/google-coral/edgetpu/raw/master/test_data/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite -O /edgetpu_model.tflite --trust-server-names
|
||||
RUN wget -q https://dl.google.com/coral/canned_models/coco_labels.txt -O /labelmap.txt --trust-server-names
|
||||
RUN wget -q https://storage.googleapis.com/download.tensorflow.org/models/tflite/coco_ssd_mobilenet_v1_1.0_quant_2018_06_29.zip -O /cpu_model.zip && \
|
||||
unzip /cpu_model.zip detect.tflite -d / && \
|
||||
mv /detect.tflite /cpu_model.tflite && \
|
||||
rm /cpu_model.zip
|
||||
# Download & build OpenCV
|
||||
RUN wget -q -P /usr/local/src/ --no-check-certificate https://github.com/opencv/opencv/archive/4.0.1.zip
|
||||
RUN cd /usr/local/src/ \
|
||||
&& unzip 4.0.1.zip \
|
||||
&& rm 4.0.1.zip \
|
||||
&& cd /usr/local/src/opencv-4.0.1/ \
|
||||
&& mkdir build \
|
||||
&& cd /usr/local/src/opencv-4.0.1/build \
|
||||
&& cmake -D CMAKE_INSTALL_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/ .. \
|
||||
&& make -j4 \
|
||||
&& make install \
|
||||
&& ldconfig \
|
||||
&& rm -rf /usr/local/src/opencv-4.0.1
|
||||
|
||||
# Download and install EdgeTPU libraries for Coral
|
||||
RUN wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names
|
||||
|
||||
RUN tar xzf edgetpu_api.tar.gz \
|
||||
&& cd edgetpu_api \
|
||||
&& cp -p libedgetpu/libedgetpu_arm32.so /usr/lib/arm-linux-gnueabihf/libedgetpu.so.1.0 \
|
||||
&& ldconfig \
|
||||
&& python3 -m pip install --no-deps "$(ls edgetpu-*-py3-none-any.whl 2>/dev/null)"
|
||||
|
||||
RUN cd /usr/local/lib/python3.6/dist-packages/edgetpu/swig/ \
|
||||
&& ln -s _edgetpu_cpp_wrapper.cpython-35m-arm-linux-gnueabihf.so _edgetpu_cpp_wrapper.cpython-36m-arm-linux-gnueabihf.so
|
||||
|
||||
# symlink the model and labels
|
||||
RUN wget https://dl.google.com/coral/canned_models/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite -O mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite --trust-server-names
|
||||
RUN wget https://dl.google.com/coral/canned_models/coco_labels.txt -O coco_labels.txt --trust-server-names
|
||||
RUN ln -s mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite /frozen_inference_graph.pb
|
||||
RUN ln -s /coco_labels.txt /label_map.pbtext
|
||||
|
||||
# Minimize image size
|
||||
RUN (apt-get autoremove -y; \
|
||||
apt-get autoclean -y)
|
||||
|
||||
WORKDIR /opt/frigate/
|
||||
ADD frigate frigate/
|
||||
COPY detect_objects.py .
|
||||
COPY benchmark.py .
|
||||
|
||||
CMD ["python3.7", "-u", "detect_objects.py"]
|
||||
CMD ["python3", "-u", "detect_objects.py"]
|
||||
|
||||
131
README.md
131
README.md
@@ -1,13 +1,14 @@
|
||||
# Frigate - Realtime Object Detection for IP Cameras
|
||||
Uses OpenCV and Tensorflow to perform realtime object detection locally for IP cameras. Designed for integration with HomeAssistant or others via MQTT.
|
||||
# Frigate - Realtime Object Detection for RTSP Cameras
|
||||
**Note:** This version requires the use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/)
|
||||
|
||||
Use of a [Google Coral USB Accelerator](https://coral.withgoogle.com/products/accelerator/) is optional, but highly recommended. On my Intel i7 processor, I can process 2-3 FPS with the CPU. The Coral can process 100+ FPS with very low CPU load.
|
||||
Uses OpenCV and Tensorflow to perform realtime object detection locally for RTSP cameras. Designed for integration with HomeAssistant or others via MQTT.
|
||||
|
||||
- Leverages multiprocessing heavily with an emphasis on realtime over processing every frame
|
||||
- Uses a very low overhead motion detection to determine where to run object detection
|
||||
- Object detection with Tensorflow runs in a separate process
|
||||
- Leverages multiprocessing and threads heavily with an emphasis on realtime over processing every frame
|
||||
- Allows you to define specific regions (squares) in the image to look for objects
|
||||
- No motion detection (for now)
|
||||
- Object detection with Tensorflow runs in a separate thread
|
||||
- Object info is published over MQTT for integration into HomeAssistant as a binary sensor
|
||||
- An endpoint is available to view an MJPEG stream for debugging, but should not be used continuously
|
||||
- An endpoint is available to view an MJPEG stream for debugging
|
||||
|
||||

|
||||
|
||||
@@ -16,112 +17,82 @@ You see multiple bounding boxes because it draws bounding boxes from all frames
|
||||
[](http://www.youtube.com/watch?v=nqHbCtyo4dY "Frigate")
|
||||
|
||||
## Getting Started
|
||||
Build the container with
|
||||
```
|
||||
docker build -t frigate .
|
||||
```
|
||||
|
||||
The `mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite` model is included and used by default. You can use your own model and labels by mounting files in the container at `/frozen_inference_graph.pb` and `/label_map.pbtext`. Models must be compatible with the Coral according to [this](https://coral.withgoogle.com/models/).
|
||||
|
||||
Run the container with
|
||||
```bash
|
||||
```
|
||||
docker run --rm \
|
||||
--privileged \
|
||||
--shm-size=512m \ # should work for a 2-3 cameras
|
||||
-v /dev/bus/usb:/dev/bus/usb \
|
||||
-v <path_to_config_dir>:/config:ro \
|
||||
-v /etc/localtime:/etc/localtime:ro \
|
||||
-p 5000:5000 \
|
||||
-e FRIGATE_RTSP_PASSWORD='password' \
|
||||
blakeblackshear/frigate:stable
|
||||
-e RTSP_PASSWORD='password' \
|
||||
frigate:latest
|
||||
```
|
||||
|
||||
Example docker-compose:
|
||||
```yaml
|
||||
```
|
||||
frigate:
|
||||
container_name: frigate
|
||||
restart: unless-stopped
|
||||
privileged: true
|
||||
shm_size: '1g' # should work for 5-7 cameras
|
||||
image: blakeblackshear/frigate:stable
|
||||
image: frigate:latest
|
||||
volumes:
|
||||
- /dev/bus/usb:/dev/bus/usb
|
||||
- /etc/localtime:/etc/localtime:ro
|
||||
- <path_to_config>:/config
|
||||
ports:
|
||||
- "5000:5000"
|
||||
environment:
|
||||
FRIGATE_RTSP_PASSWORD: "password"
|
||||
RTSP_PASSWORD: "password"
|
||||
```
|
||||
|
||||
A `config.yml` file must exist in the `config` directory. See example [here](config/config.example.yml) and device specific info can be found [here](docs/DEVICES.md).
|
||||
A `config.yml` file must exist in the `config` directory. See example [here](config/config.yml).
|
||||
|
||||
Access the mjpeg stream at `http://localhost:5000/<camera_name>` and the best snapshot for any object type with at `http://localhost:5000/<camera_name>/<object_name>/best.jpg`
|
||||
|
||||
Debug info is available at `http://localhost:5000/debug/stats`
|
||||
Access the mjpeg stream at `http://localhost:5000/<camera_name>` and the best person snapshot at `http://localhost:5000/<camera_name>/best_person.jpg`
|
||||
|
||||
## Integration with HomeAssistant
|
||||
```
|
||||
camera:
|
||||
- name: Camera Last Person
|
||||
platform: mqtt
|
||||
topic: frigate/<camera_name>/person/snapshot
|
||||
- name: Camera Last Car
|
||||
platform: mqtt
|
||||
topic: frigate/<camera_name>/car/snapshot
|
||||
platform: generic
|
||||
still_image_url: http://<ip>:5000/<camera_name>/best_person.jpg
|
||||
|
||||
binary_sensor:
|
||||
- name: Camera Person
|
||||
platform: mqtt
|
||||
state_topic: "frigate/<camera_name>/person"
|
||||
state_topic: "frigate/<camera_name>/objects"
|
||||
value_template: '{{ value_json.person }}'
|
||||
device_class: motion
|
||||
availability_topic: "frigate/available"
|
||||
|
||||
automation:
|
||||
- alias: Alert me if a person is detected while armed away
|
||||
trigger:
|
||||
platform: state
|
||||
entity_id: binary_sensor.camera_person
|
||||
from: 'off'
|
||||
to: 'on'
|
||||
condition:
|
||||
- condition: state
|
||||
entity_id: alarm_control_panel.home_alarm
|
||||
state: armed_away
|
||||
action:
|
||||
- service: notify.user_telegram
|
||||
data:
|
||||
message: "A person was detected."
|
||||
data:
|
||||
photo:
|
||||
- url: http://<ip>:5000/<camera_name>/person/best.jpg
|
||||
caption: A person was detected.
|
||||
|
||||
sensor:
|
||||
- platform: rest
|
||||
name: Frigate Debug
|
||||
resource: http://localhost:5000/debug/stats
|
||||
scan_interval: 5
|
||||
json_attributes:
|
||||
- back
|
||||
- coral
|
||||
value_template: 'OK'
|
||||
- platform: template
|
||||
sensors:
|
||||
back_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["back"]["fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
back_skipped_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["back"]["skipped_fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
back_detection_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["back"]["detection_fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
frigate_coral_fps:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["fps"] }}'
|
||||
unit_of_measurement: 'FPS'
|
||||
frigate_coral_inference:
|
||||
value_template: '{{ states.sensor.frigate_debug.attributes["coral"]["inference_speed"] }}'
|
||||
unit_of_measurement: 'ms'
|
||||
```
|
||||
## Using a custom model
|
||||
Models for both CPU and EdgeTPU (Coral) are bundled in the image. You can use your own models with volume mounts:
|
||||
- CPU Model: `/cpu_model.tflite`
|
||||
- EdgeTPU Model: `/edgetpu_model.tflite`
|
||||
- Labels: `/labelmap.txt`
|
||||
|
||||
## Tips
|
||||
- Lower the framerate of the video feed on the camera to reduce the CPU usage for capturing the feed
|
||||
- Lower the framerate of the RTSP feed on the camera to reduce the CPU usage for capturing the feed
|
||||
|
||||
## Future improvements
|
||||
- [x] Remove motion detection for now
|
||||
- [x] Try running object detection in a thread rather than a process
|
||||
- [x] Implement min person size again
|
||||
- [x] Switch to a config file
|
||||
- [x] Handle multiple cameras in the same container
|
||||
- [ ] Attempt to figure out coral symlinking
|
||||
- [ ] Add object list to config with min scores for mqtt
|
||||
- [ ] Move mjpeg encoding to a separate process
|
||||
- [ ] Simplify motion detection (check entire image against mask, resize instead of gaussian blur)
|
||||
- [ ] See if motion detection is even worth running
|
||||
- [ ] Scan for people across entire image rather than specfic regions
|
||||
- [ ] Dynamically resize detection area and follow people
|
||||
- [ ] Add ability to turn detection on and off via MQTT
|
||||
- [ ] Output movie clips of people for notifications, etc.
|
||||
- [ ] Integrate with homeassistant push camera
|
||||
- [ ] Merge bounding boxes that span multiple regions
|
||||
- [ ] Implement mode to save labeled objects for training
|
||||
- [ ] Try and reduce CPU usage by simplifying the tensorflow model to just include the objects we care about
|
||||
- [ ] Look into GPU accelerated decoding of RTSP stream
|
||||
- [ ] Send video over a socket and use JSMPEG
|
||||
- [x] Look into neural compute stick
|
||||
|
||||
79
benchmark.py
79
benchmark.py
@@ -1,79 +0,0 @@
|
||||
import os
|
||||
from statistics import mean
|
||||
import multiprocessing as mp
|
||||
import numpy as np
|
||||
import datetime
|
||||
from frigate.edgetpu import ObjectDetector, EdgeTPUProcess, RemoteObjectDetector, load_labels
|
||||
|
||||
my_frame = np.expand_dims(np.full((300,300,3), 1, np.uint8), axis=0)
|
||||
labels = load_labels('/labelmap.txt')
|
||||
|
||||
######
|
||||
# Minimal same process runner
|
||||
######
|
||||
# object_detector = ObjectDetector()
|
||||
# tensor_input = np.expand_dims(np.full((300,300,3), 0, np.uint8), axis=0)
|
||||
|
||||
# start = datetime.datetime.now().timestamp()
|
||||
|
||||
# frame_times = []
|
||||
# for x in range(0, 1000):
|
||||
# start_frame = datetime.datetime.now().timestamp()
|
||||
|
||||
# tensor_input[:] = my_frame
|
||||
# detections = object_detector.detect_raw(tensor_input)
|
||||
# parsed_detections = []
|
||||
# for d in detections:
|
||||
# if d[1] < 0.4:
|
||||
# break
|
||||
# parsed_detections.append((
|
||||
# labels[int(d[0])],
|
||||
# float(d[1]),
|
||||
# (d[2], d[3], d[4], d[5])
|
||||
# ))
|
||||
# frame_times.append(datetime.datetime.now().timestamp()-start_frame)
|
||||
|
||||
# duration = datetime.datetime.now().timestamp()-start
|
||||
# print(f"Processed for {duration:.2f} seconds.")
|
||||
# print(f"Average frame processing time: {mean(frame_times)*1000:.2f}ms")
|
||||
|
||||
######
|
||||
# Separate process runner
|
||||
######
|
||||
def start(id, num_detections, detection_queue):
|
||||
object_detector = RemoteObjectDetector(str(id), '/labelmap.txt', detection_queue)
|
||||
start = datetime.datetime.now().timestamp()
|
||||
|
||||
frame_times = []
|
||||
for x in range(0, num_detections):
|
||||
start_frame = datetime.datetime.now().timestamp()
|
||||
detections = object_detector.detect(my_frame)
|
||||
frame_times.append(datetime.datetime.now().timestamp()-start_frame)
|
||||
|
||||
duration = datetime.datetime.now().timestamp()-start
|
||||
print(f"{id} - Processed for {duration:.2f} seconds.")
|
||||
print(f"{id} - Average frame processing time: {mean(frame_times)*1000:.2f}ms")
|
||||
|
||||
edgetpu_process = EdgeTPUProcess()
|
||||
|
||||
# start(1, 1000, edgetpu_process.detect_lock, edgetpu_process.detect_ready, edgetpu_process.frame_ready)
|
||||
|
||||
####
|
||||
# Multiple camera processes
|
||||
####
|
||||
camera_processes = []
|
||||
for x in range(0, 10):
|
||||
camera_process = mp.Process(target=start, args=(x, 100, edgetpu_process.detection_queue))
|
||||
camera_process.daemon = True
|
||||
camera_processes.append(camera_process)
|
||||
|
||||
start = datetime.datetime.now().timestamp()
|
||||
|
||||
for p in camera_processes:
|
||||
p.start()
|
||||
|
||||
for p in camera_processes:
|
||||
p.join()
|
||||
|
||||
duration = datetime.datetime.now().timestamp()-start
|
||||
print(f"Total - Processed for {duration:.2f} seconds.")
|
||||
@@ -1,136 +0,0 @@
|
||||
web_port: 5000
|
||||
|
||||
mqtt:
|
||||
host: mqtt.server.com
|
||||
topic_prefix: frigate
|
||||
# client_id: frigate # Optional -- set to override default client id of 'frigate' if running multiple instances
|
||||
# user: username # Optional
|
||||
#################
|
||||
## Environment variables that begin with 'FRIGATE_' may be referenced in {}.
|
||||
## password: '{FRIGATE_MQTT_PASSWORD}'
|
||||
#################
|
||||
# password: password # Optional
|
||||
|
||||
#################
|
||||
# Default ffmpeg args. Optional and can be overwritten per camera.
|
||||
# Should work with most RTSP cameras that send h264 video
|
||||
# Built from the properties below with:
|
||||
# "ffmpeg" + global_args + input_args + "-i" + input + output_args
|
||||
#################
|
||||
# ffmpeg:
|
||||
# global_args:
|
||||
# - -hide_banner
|
||||
# - -loglevel
|
||||
# - panic
|
||||
# hwaccel_args: []
|
||||
# input_args:
|
||||
# - -avoid_negative_ts
|
||||
# - make_zero
|
||||
# - -fflags
|
||||
# - nobuffer
|
||||
# - -flags
|
||||
# - low_delay
|
||||
# - -strict
|
||||
# - experimental
|
||||
# - -fflags
|
||||
# - +genpts+discardcorrupt
|
||||
# - -vsync
|
||||
# - drop
|
||||
# - -rtsp_transport
|
||||
# - tcp
|
||||
# - -stimeout
|
||||
# - '5000000'
|
||||
# - -use_wallclock_as_timestamps
|
||||
# - '1'
|
||||
# output_args:
|
||||
# - -f
|
||||
# - rawvideo
|
||||
# - -pix_fmt
|
||||
# - rgb24
|
||||
|
||||
####################
|
||||
# Global object configuration. Applies to all cameras
|
||||
# unless overridden at the camera levels.
|
||||
# Keys must be valid labels. By default, the model uses coco (https://dl.google.com/coral/canned_models/coco_labels.txt).
|
||||
# All labels from the model are reported over MQTT. These values are used to filter out false positives.
|
||||
# min_area (optional): minimum width*height of the bounding box for the detected person
|
||||
# max_area (optional): maximum width*height of the bounding box for the detected person
|
||||
# threshold (optional): The minimum decimal percentage (50% hit = 0.5) for the confidence from tensorflow
|
||||
####################
|
||||
objects:
|
||||
track:
|
||||
- person
|
||||
- car
|
||||
- truck
|
||||
filters:
|
||||
person:
|
||||
min_area: 5000
|
||||
max_area: 100000
|
||||
threshold: 0.5
|
||||
|
||||
cameras:
|
||||
back:
|
||||
ffmpeg:
|
||||
################
|
||||
# Source passed to ffmpeg after the -i parameter. Supports anything compatible with OpenCV and FFmpeg.
|
||||
# Environment variables that begin with 'FRIGATE_' may be referenced in {}
|
||||
################
|
||||
input: rtsp://viewer:{FRIGATE_RTSP_PASSWORD}@10.0.10.10:554/cam/realmonitor?channel=1&subtype=2
|
||||
#################
|
||||
# These values will override default values for just this camera
|
||||
#################
|
||||
# global_args: []
|
||||
# hwaccel_args: []
|
||||
# input_args: []
|
||||
# output_args: []
|
||||
|
||||
################
|
||||
## Optionally specify the resolution of the video feed. Frigate will try to auto detect if not specified
|
||||
################
|
||||
# height: 1280
|
||||
# width: 720
|
||||
|
||||
################
|
||||
## Optional mask. Must be the same aspect ratio as your video feed.
|
||||
##
|
||||
## The mask works by looking at the bottom center of the bounding box for the detected
|
||||
## person in the image. If that pixel in the mask is a black pixel, it ignores it as a
|
||||
## false positive. In my mask, the grass and driveway visible from my backdoor camera
|
||||
## are white. The garage doors, sky, and trees (anywhere it would be impossible for a
|
||||
## person to stand) are black.
|
||||
##
|
||||
## Masked areas are also ignored for motion detection.
|
||||
################
|
||||
# mask: back-mask.bmp
|
||||
|
||||
################
|
||||
# Allows you to limit the framerate within frigate for cameras that do not support
|
||||
# custom framerates. A value of 1 tells frigate to look at every frame, 2 every 2nd frame,
|
||||
# 3 every 3rd frame, etc.
|
||||
################
|
||||
take_frame: 1
|
||||
|
||||
################
|
||||
# The expected framerate for the camera. Frigate will try and ensure it maintains this framerate
|
||||
# by dropping frames as necessary. Setting this lower than the actual framerate will allow frigate
|
||||
# to process every frame at the expense of realtime processing.
|
||||
################
|
||||
fps: 5
|
||||
|
||||
################
|
||||
# Configuration for the snapshots in the debug view and mqtt
|
||||
################
|
||||
snapshots:
|
||||
show_timestamp: True
|
||||
|
||||
################
|
||||
# Camera level object config. This config is merged with the global config above.
|
||||
################
|
||||
objects:
|
||||
track:
|
||||
- person
|
||||
filters:
|
||||
person:
|
||||
min_area: 5000
|
||||
max_area: 100000
|
||||
threshold: 0.5
|
||||
34
config/config.yml
Normal file
34
config/config.yml
Normal file
@@ -0,0 +1,34 @@
|
||||
web_port: 5000
|
||||
|
||||
mqtt:
|
||||
host: mqtt.server.com
|
||||
topic_prefix: frigate
|
||||
# user: username # Optional -- Uncomment for use
|
||||
# password: password # Optional -- Uncomment for use
|
||||
|
||||
cameras:
|
||||
back:
|
||||
rtsp:
|
||||
user: viewer
|
||||
host: 10.0.10.10
|
||||
port: 554
|
||||
# values that begin with a "$" will be replaced with environment variable
|
||||
password: $RTSP_PASSWORD
|
||||
path: /cam/realmonitor?channel=1&subtype=2
|
||||
mask: back-mask.bmp
|
||||
regions:
|
||||
- size: 350
|
||||
x_offset: 0
|
||||
y_offset: 300
|
||||
min_person_area: 5000
|
||||
threshold: 0.5
|
||||
- size: 400
|
||||
x_offset: 350
|
||||
y_offset: 250
|
||||
min_person_area: 2000
|
||||
threshold: 0.5
|
||||
- size: 400
|
||||
x_offset: 750
|
||||
y_offset: 250
|
||||
min_person_area: 2000
|
||||
threshold: 0.5
|
||||
@@ -1,26 +1,13 @@
|
||||
import os
|
||||
import sys
|
||||
import traceback
|
||||
import signal
|
||||
import cv2
|
||||
import time
|
||||
import datetime
|
||||
import queue
|
||||
import yaml
|
||||
import threading
|
||||
import multiprocessing as mp
|
||||
import subprocess as sp
|
||||
import numpy as np
|
||||
import logging
|
||||
from flask import Flask, Response, make_response, jsonify, request
|
||||
from flask import Flask, Response, make_response
|
||||
import paho.mqtt.client as mqtt
|
||||
|
||||
from frigate.video import track_camera, get_ffmpeg_input, get_frame_shape, CameraCapture, start_or_restart_ffmpeg
|
||||
from frigate.object_processing import TrackedObjectProcessor
|
||||
from frigate.util import EventsPerSecond
|
||||
from frigate.edgetpu import EdgeTPUProcess
|
||||
|
||||
FRIGATE_VARS = {k: v for k, v in os.environ.items() if k.startswith('FRIGATE_')}
|
||||
from frigate.video import Camera
|
||||
from frigate.object_detection import PreppedQueueProcessor
|
||||
|
||||
with open('/config/config.yml') as f:
|
||||
CONFIG = yaml.safe_load(f)
|
||||
@@ -30,120 +17,17 @@ MQTT_PORT = CONFIG.get('mqtt', {}).get('port', 1883)
|
||||
MQTT_TOPIC_PREFIX = CONFIG.get('mqtt', {}).get('topic_prefix', 'frigate')
|
||||
MQTT_USER = CONFIG.get('mqtt', {}).get('user')
|
||||
MQTT_PASS = CONFIG.get('mqtt', {}).get('password')
|
||||
if not MQTT_PASS is None:
|
||||
MQTT_PASS = MQTT_PASS.format(**FRIGATE_VARS)
|
||||
MQTT_CLIENT_ID = CONFIG.get('mqtt', {}).get('client_id', 'frigate')
|
||||
|
||||
# Set the default FFmpeg config
|
||||
FFMPEG_CONFIG = CONFIG.get('ffmpeg', {})
|
||||
FFMPEG_DEFAULT_CONFIG = {
|
||||
'global_args': FFMPEG_CONFIG.get('global_args',
|
||||
['-hide_banner','-loglevel','panic']),
|
||||
'hwaccel_args': FFMPEG_CONFIG.get('hwaccel_args',
|
||||
[]),
|
||||
'input_args': FFMPEG_CONFIG.get('input_args',
|
||||
['-avoid_negative_ts', 'make_zero',
|
||||
'-fflags', 'nobuffer',
|
||||
'-flags', 'low_delay',
|
||||
'-strict', 'experimental',
|
||||
'-fflags', '+genpts+discardcorrupt',
|
||||
'-vsync', 'drop',
|
||||
'-rtsp_transport', 'tcp',
|
||||
'-stimeout', '5000000',
|
||||
'-use_wallclock_as_timestamps', '1']),
|
||||
'output_args': FFMPEG_CONFIG.get('output_args',
|
||||
['-f', 'rawvideo',
|
||||
'-pix_fmt', 'rgb24'])
|
||||
}
|
||||
|
||||
GLOBAL_OBJECT_CONFIG = CONFIG.get('objects', {})
|
||||
|
||||
WEB_PORT = CONFIG.get('web_port', 5000)
|
||||
DEBUG = (CONFIG.get('debug', '0') == '1')
|
||||
|
||||
def start_plasma_store():
|
||||
plasma_cmd = ['plasma_store', '-m', '400000000', '-s', '/tmp/plasma']
|
||||
plasma_process = sp.Popen(plasma_cmd, stdout=sp.DEVNULL)
|
||||
time.sleep(1)
|
||||
rc = plasma_process.poll()
|
||||
if rc is not None:
|
||||
return None
|
||||
return plasma_process
|
||||
|
||||
class CameraWatchdog(threading.Thread):
|
||||
def __init__(self, camera_processes, config, tflite_process, tracked_objects_queue, plasma_process):
|
||||
threading.Thread.__init__(self)
|
||||
self.camera_processes = camera_processes
|
||||
self.config = config
|
||||
self.tflite_process = tflite_process
|
||||
self.tracked_objects_queue = tracked_objects_queue
|
||||
self.plasma_process = plasma_process
|
||||
|
||||
def run(self):
|
||||
time.sleep(10)
|
||||
while True:
|
||||
# wait a bit before checking
|
||||
time.sleep(10)
|
||||
|
||||
# check the plasma process
|
||||
rc = self.plasma_process.poll()
|
||||
if rc != None:
|
||||
print(f"plasma_process exited unexpectedly with {rc}")
|
||||
self.plasma_process = start_plasma_store()
|
||||
|
||||
# check the detection process
|
||||
if (self.tflite_process.detection_start.value > 0.0 and
|
||||
datetime.datetime.now().timestamp() - self.tflite_process.detection_start.value > 10):
|
||||
print("Detection appears to be stuck. Restarting detection process")
|
||||
self.tflite_process.start_or_restart()
|
||||
elif not self.tflite_process.detect_process.is_alive():
|
||||
print("Detection appears to have stopped. Restarting detection process")
|
||||
self.tflite_process.start_or_restart()
|
||||
|
||||
# check the camera processes
|
||||
for name, camera_process in self.camera_processes.items():
|
||||
process = camera_process['process']
|
||||
if not process.is_alive():
|
||||
print(f"Track process for {name} is not alive. Starting again...")
|
||||
camera_process['fps'].value = float(self.config[name]['fps'])
|
||||
camera_process['skipped_fps'].value = 0.0
|
||||
camera_process['detection_fps'].value = 0.0
|
||||
camera_process['read_start'].value = 0.0
|
||||
process = mp.Process(target=track_camera, args=(name, self.config[name], GLOBAL_OBJECT_CONFIG, camera_process['frame_queue'],
|
||||
camera_process['frame_shape'], self.tflite_process.detection_queue, self.tracked_objects_queue,
|
||||
camera_process['fps'], camera_process['skipped_fps'], camera_process['detection_fps'],
|
||||
camera_process['read_start']))
|
||||
process.daemon = True
|
||||
camera_process['process'] = process
|
||||
process.start()
|
||||
print(f"Track process started for {name}: {process.pid}")
|
||||
|
||||
if not camera_process['capture_thread'].is_alive():
|
||||
frame_shape = camera_process['frame_shape']
|
||||
frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
ffmpeg_process = start_or_restart_ffmpeg(camera_process['ffmpeg_cmd'], frame_size)
|
||||
camera_capture = CameraCapture(name, ffmpeg_process, frame_shape, camera_process['frame_queue'],
|
||||
camera_process['take_frame'], camera_process['camera_fps'])
|
||||
camera_capture.start()
|
||||
camera_process['ffmpeg_process'] = ffmpeg_process
|
||||
camera_process['capture_thread'] = camera_capture
|
||||
|
||||
def main():
|
||||
# connect to mqtt and setup last will
|
||||
def on_connect(client, userdata, flags, rc):
|
||||
print("On connect called")
|
||||
if rc != 0:
|
||||
if rc == 3:
|
||||
print ("MQTT Server unavailable")
|
||||
elif rc == 4:
|
||||
print ("MQTT Bad username or password")
|
||||
elif rc == 5:
|
||||
print ("MQTT Not authorized")
|
||||
else:
|
||||
print ("Unable to connect to MQTT: Connection refused. Error code: " + str(rc))
|
||||
# publish a message to signal that the service is running
|
||||
client.publish(MQTT_TOPIC_PREFIX+'/available', 'online', retain=True)
|
||||
client = mqtt.Client(client_id=MQTT_CLIENT_ID)
|
||||
client = mqtt.Client()
|
||||
client.on_connect = on_connect
|
||||
client.will_set(MQTT_TOPIC_PREFIX+'/available', payload='offline', qos=1, retain=True)
|
||||
if not MQTT_USER is None:
|
||||
@@ -151,187 +35,56 @@ def main():
|
||||
client.connect(MQTT_HOST, MQTT_PORT, 60)
|
||||
client.loop_start()
|
||||
|
||||
plasma_process = start_plasma_store()
|
||||
# Queue for prepped frames, max size set to (number of cameras * 5)
|
||||
max_queue_size = len(CONFIG['cameras'].items())*5
|
||||
prepped_frame_queue = queue.Queue(max_queue_size)
|
||||
|
||||
##
|
||||
# Setup config defaults for cameras
|
||||
##
|
||||
cameras = {}
|
||||
for name, config in CONFIG['cameras'].items():
|
||||
config['snapshots'] = {
|
||||
'show_timestamp': config.get('snapshots', {}).get('show_timestamp', True)
|
||||
}
|
||||
cameras[name] = Camera(name, config, prepped_frame_queue, client, MQTT_TOPIC_PREFIX)
|
||||
|
||||
# Queue for cameras to push tracked objects to
|
||||
tracked_objects_queue = mp.SimpleQueue()
|
||||
prepped_queue_processor = PreppedQueueProcessor(
|
||||
cameras,
|
||||
prepped_frame_queue
|
||||
)
|
||||
prepped_queue_processor.start()
|
||||
|
||||
# Start the shared tflite process
|
||||
tflite_process = EdgeTPUProcess()
|
||||
|
||||
# start the camera processes
|
||||
camera_processes = {}
|
||||
for name, config in CONFIG['cameras'].items():
|
||||
# Merge the ffmpeg config with the global config
|
||||
ffmpeg = config.get('ffmpeg', {})
|
||||
ffmpeg_input = get_ffmpeg_input(ffmpeg['input'])
|
||||
ffmpeg_global_args = ffmpeg.get('global_args', FFMPEG_DEFAULT_CONFIG['global_args'])
|
||||
ffmpeg_hwaccel_args = ffmpeg.get('hwaccel_args', FFMPEG_DEFAULT_CONFIG['hwaccel_args'])
|
||||
ffmpeg_input_args = ffmpeg.get('input_args', FFMPEG_DEFAULT_CONFIG['input_args'])
|
||||
ffmpeg_output_args = ffmpeg.get('output_args', FFMPEG_DEFAULT_CONFIG['output_args'])
|
||||
ffmpeg_cmd = (['ffmpeg'] +
|
||||
ffmpeg_global_args +
|
||||
ffmpeg_hwaccel_args +
|
||||
ffmpeg_input_args +
|
||||
['-i', ffmpeg_input] +
|
||||
ffmpeg_output_args +
|
||||
['pipe:'])
|
||||
|
||||
if 'width' in config and 'height' in config:
|
||||
frame_shape = (config['height'], config['width'], 3)
|
||||
else:
|
||||
frame_shape = get_frame_shape(ffmpeg_input)
|
||||
|
||||
frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
take_frame = config.get('take_frame', 1)
|
||||
|
||||
ffmpeg_process = start_or_restart_ffmpeg(ffmpeg_cmd, frame_size)
|
||||
frame_queue = mp.SimpleQueue()
|
||||
camera_fps = EventsPerSecond()
|
||||
camera_fps.start()
|
||||
camera_capture = CameraCapture(name, ffmpeg_process, frame_shape, frame_queue, take_frame, camera_fps)
|
||||
camera_capture.start()
|
||||
|
||||
camera_processes[name] = {
|
||||
'camera_fps': camera_fps,
|
||||
'take_frame': take_frame,
|
||||
'fps': mp.Value('d', float(config['fps'])),
|
||||
'skipped_fps': mp.Value('d', 0.0),
|
||||
'detection_fps': mp.Value('d', 0.0),
|
||||
'read_start': mp.Value('d', 0.0),
|
||||
'ffmpeg_process': ffmpeg_process,
|
||||
'ffmpeg_cmd': ffmpeg_cmd,
|
||||
'frame_queue': frame_queue,
|
||||
'frame_shape': frame_shape,
|
||||
'capture_thread': camera_capture
|
||||
}
|
||||
|
||||
camera_process = mp.Process(target=track_camera, args=(name, config, GLOBAL_OBJECT_CONFIG, frame_queue, frame_shape,
|
||||
tflite_process.detection_queue, tracked_objects_queue, camera_processes[name]['fps'],
|
||||
camera_processes[name]['skipped_fps'], camera_processes[name]['detection_fps'],
|
||||
camera_processes[name]['read_start']))
|
||||
camera_process.daemon = True
|
||||
camera_processes[name]['process'] = camera_process
|
||||
|
||||
for name, camera_process in camera_processes.items():
|
||||
camera_process['process'].start()
|
||||
print(f"Camera_process started for {name}: {camera_process['process'].pid}")
|
||||
|
||||
object_processor = TrackedObjectProcessor(CONFIG['cameras'], client, MQTT_TOPIC_PREFIX, tracked_objects_queue)
|
||||
object_processor.start()
|
||||
|
||||
camera_watchdog = CameraWatchdog(camera_processes, CONFIG['cameras'], tflite_process, tracked_objects_queue, plasma_process)
|
||||
camera_watchdog.start()
|
||||
for name, camera in cameras.items():
|
||||
camera.start()
|
||||
print("Capture process for {}: {}".format(name, camera.get_capture_pid()))
|
||||
|
||||
# create a flask app that encodes frames a mjpeg on demand
|
||||
app = Flask(__name__)
|
||||
log = logging.getLogger('werkzeug')
|
||||
log.setLevel(logging.ERROR)
|
||||
|
||||
@app.route('/')
|
||||
def ishealthy():
|
||||
# return a healh
|
||||
return "Frigate is running. Alive and healthy!"
|
||||
|
||||
@app.route('/debug/stack')
|
||||
def processor_stack():
|
||||
frame = sys._current_frames().get(object_processor.ident, None)
|
||||
if frame:
|
||||
return "<br>".join(traceback.format_stack(frame)), 200
|
||||
else:
|
||||
return "no frame found", 200
|
||||
|
||||
@app.route('/debug/print_stack')
|
||||
def print_stack():
|
||||
pid = int(request.args.get('pid', 0))
|
||||
if pid == 0:
|
||||
return "missing pid", 200
|
||||
else:
|
||||
os.kill(pid, signal.SIGUSR1)
|
||||
return "check logs", 200
|
||||
|
||||
@app.route('/debug/stats')
|
||||
def stats():
|
||||
stats = {}
|
||||
|
||||
total_detection_fps = 0
|
||||
|
||||
for name, camera_stats in camera_processes.items():
|
||||
total_detection_fps += camera_stats['detection_fps'].value
|
||||
stats[name] = {
|
||||
'fps': round(camera_stats['fps'].value, 2),
|
||||
'skipped_fps': round(camera_stats['skipped_fps'].value, 2),
|
||||
'detection_fps': round(camera_stats['detection_fps'].value, 2),
|
||||
'read_start': camera_stats['read_start'].value,
|
||||
'pid': camera_stats['process'].pid,
|
||||
'ffmpeg_pid': camera_stats['ffmpeg_process'].pid
|
||||
}
|
||||
|
||||
stats['coral'] = {
|
||||
'fps': round(total_detection_fps, 2),
|
||||
'inference_speed': round(tflite_process.avg_inference_speed.value*1000, 2),
|
||||
'detection_start': tflite_process.detection_start.value,
|
||||
'pid': tflite_process.detect_process.pid
|
||||
}
|
||||
|
||||
rc = camera_watchdog.plasma_process.poll()
|
||||
stats['plasma_store_rc'] = rc
|
||||
|
||||
return jsonify(stats)
|
||||
|
||||
@app.route('/<camera_name>/<label>/best.jpg')
|
||||
def best(camera_name, label):
|
||||
if camera_name in CONFIG['cameras']:
|
||||
best_frame = object_processor.get_best(camera_name, label)
|
||||
if best_frame is None:
|
||||
best_frame = np.zeros((720,1280,3), np.uint8)
|
||||
best_frame = cv2.cvtColor(best_frame, cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
@app.route('/<camera_name>/best_person.jpg')
|
||||
def best_person(camera_name):
|
||||
best_person_frame = cameras[camera_name].get_best_person()
|
||||
if best_person_frame is None:
|
||||
best_person_frame = np.zeros((720,1280,3), np.uint8)
|
||||
ret, jpg = cv2.imencode('.jpg', best_person_frame)
|
||||
response = make_response(jpg.tobytes())
|
||||
response.headers['Content-Type'] = 'image/jpg'
|
||||
return response
|
||||
else:
|
||||
return "Camera named {} not found".format(camera_name), 404
|
||||
|
||||
@app.route('/<camera_name>')
|
||||
def mjpeg_feed(camera_name):
|
||||
fps = int(request.args.get('fps', '3'))
|
||||
height = int(request.args.get('h', '360'))
|
||||
if camera_name in CONFIG['cameras']:
|
||||
# return a multipart response
|
||||
return Response(imagestream(camera_name, fps, height),
|
||||
return Response(imagestream(camera_name),
|
||||
mimetype='multipart/x-mixed-replace; boundary=frame')
|
||||
else:
|
||||
return "Camera named {} not found".format(camera_name), 404
|
||||
|
||||
def imagestream(camera_name, fps, height):
|
||||
def imagestream(camera_name):
|
||||
while True:
|
||||
# max out at specified FPS
|
||||
time.sleep(1/fps)
|
||||
frame = object_processor.get_current_frame(camera_name)
|
||||
if frame is None:
|
||||
frame = np.zeros((height,int(height*16/9),3), np.uint8)
|
||||
|
||||
frame = cv2.resize(frame, dsize=(int(height*16/9), height), interpolation=cv2.INTER_LINEAR)
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
# max out at 5 FPS
|
||||
time.sleep(0.2)
|
||||
frame = cameras[camera_name].get_current_frame_with_objects()
|
||||
# encode the image into a jpg
|
||||
ret, jpg = cv2.imencode('.jpg', frame)
|
||||
yield (b'--frame\r\n'
|
||||
b'Content-Type: image/jpeg\r\n\r\n' + jpg.tobytes() + b'\r\n\r\n')
|
||||
|
||||
app.run(host='0.0.0.0', port=WEB_PORT, debug=False)
|
||||
|
||||
object_processor.join()
|
||||
|
||||
plasma_process.terminate()
|
||||
camera.join()
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
BIN
diagram.png
BIN
diagram.png
{kind=link}
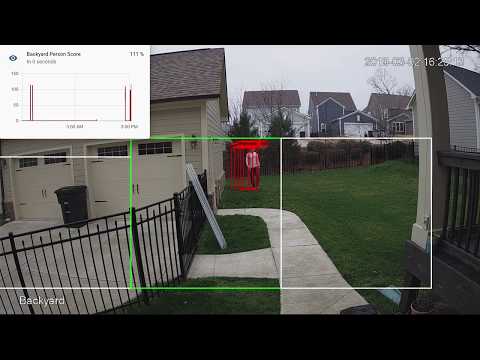
Binary file not shown.
|
Before Width: | Height: | Size: 132 KiB After Width: | Height: | Size: 283 KiB |
@@ -1,74 +0,0 @@
|
||||
# Configuration Examples
|
||||
|
||||
### Default (most RTSP cameras)
|
||||
This is the default ffmpeg command and should work with most RTSP cameras that send h264 video
|
||||
```yaml
|
||||
ffmpeg:
|
||||
global_args:
|
||||
- -hide_banner
|
||||
- -loglevel
|
||||
- panic
|
||||
hwaccel_args: []
|
||||
input_args:
|
||||
- -avoid_negative_ts
|
||||
- make_zero
|
||||
- -fflags
|
||||
- nobuffer
|
||||
- -flags
|
||||
- low_delay
|
||||
- -strict
|
||||
- experimental
|
||||
- -fflags
|
||||
- +genpts+discardcorrupt
|
||||
- -vsync
|
||||
- drop
|
||||
- -rtsp_transport
|
||||
- tcp
|
||||
- -stimeout
|
||||
- '5000000'
|
||||
- -use_wallclock_as_timestamps
|
||||
- '1'
|
||||
output_args:
|
||||
- -vf
|
||||
- mpdecimate
|
||||
- -f
|
||||
- rawvideo
|
||||
- -pix_fmt
|
||||
- rgb24
|
||||
```
|
||||
|
||||
### RTMP Cameras
|
||||
The input parameters need to be adjusted for RTMP cameras
|
||||
```yaml
|
||||
ffmpeg:
|
||||
input_args:
|
||||
- -avoid_negative_ts
|
||||
- make_zero
|
||||
- -fflags
|
||||
- nobuffer
|
||||
- -flags
|
||||
- low_delay
|
||||
- -strict
|
||||
- experimental
|
||||
- -fflags
|
||||
- +genpts+discardcorrupt
|
||||
- -vsync
|
||||
- drop
|
||||
- -use_wallclock_as_timestamps
|
||||
- '1'
|
||||
```
|
||||
|
||||
|
||||
### Hardware Acceleration
|
||||
|
||||
Intel Quicksync
|
||||
```yaml
|
||||
ffmpeg:
|
||||
hwaccel_args:
|
||||
- -hwaccel
|
||||
- vaapi
|
||||
- -hwaccel_device
|
||||
- /dev/dri/renderD128
|
||||
- -hwaccel_output_format
|
||||
- yuv420p
|
||||
```
|
||||
@@ -1,142 +0,0 @@
|
||||
import os
|
||||
import datetime
|
||||
import hashlib
|
||||
import multiprocessing as mp
|
||||
import numpy as np
|
||||
import pyarrow.plasma as plasma
|
||||
import tflite_runtime.interpreter as tflite
|
||||
from tflite_runtime.interpreter import load_delegate
|
||||
from frigate.util import EventsPerSecond, listen
|
||||
|
||||
def load_labels(path, encoding='utf-8'):
|
||||
"""Loads labels from file (with or without index numbers).
|
||||
Args:
|
||||
path: path to label file.
|
||||
encoding: label file encoding.
|
||||
Returns:
|
||||
Dictionary mapping indices to labels.
|
||||
"""
|
||||
with open(path, 'r', encoding=encoding) as f:
|
||||
lines = f.readlines()
|
||||
if not lines:
|
||||
return {}
|
||||
|
||||
if lines[0].split(' ', maxsplit=1)[0].isdigit():
|
||||
pairs = [line.split(' ', maxsplit=1) for line in lines]
|
||||
return {int(index): label.strip() for index, label in pairs}
|
||||
else:
|
||||
return {index: line.strip() for index, line in enumerate(lines)}
|
||||
|
||||
class ObjectDetector():
|
||||
def __init__(self):
|
||||
edge_tpu_delegate = None
|
||||
try:
|
||||
edge_tpu_delegate = load_delegate('libedgetpu.so.1.0')
|
||||
except ValueError:
|
||||
print("No EdgeTPU detected. Falling back to CPU.")
|
||||
|
||||
if edge_tpu_delegate is None:
|
||||
self.interpreter = tflite.Interpreter(
|
||||
model_path='/cpu_model.tflite')
|
||||
else:
|
||||
self.interpreter = tflite.Interpreter(
|
||||
model_path='/edgetpu_model.tflite',
|
||||
experimental_delegates=[edge_tpu_delegate])
|
||||
|
||||
self.interpreter.allocate_tensors()
|
||||
|
||||
self.tensor_input_details = self.interpreter.get_input_details()
|
||||
self.tensor_output_details = self.interpreter.get_output_details()
|
||||
|
||||
def detect_raw(self, tensor_input):
|
||||
self.interpreter.set_tensor(self.tensor_input_details[0]['index'], tensor_input)
|
||||
self.interpreter.invoke()
|
||||
boxes = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[0]['index']))
|
||||
label_codes = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[1]['index']))
|
||||
scores = np.squeeze(self.interpreter.get_tensor(self.tensor_output_details[2]['index']))
|
||||
|
||||
detections = np.zeros((20,6), np.float32)
|
||||
for i, score in enumerate(scores):
|
||||
detections[i] = [label_codes[i], score, boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]]
|
||||
|
||||
return detections
|
||||
|
||||
def run_detector(detection_queue, avg_speed, start):
|
||||
print(f"Starting detection process: {os.getpid()}")
|
||||
listen()
|
||||
plasma_client = plasma.connect("/tmp/plasma")
|
||||
object_detector = ObjectDetector()
|
||||
|
||||
while True:
|
||||
object_id_str = detection_queue.get()
|
||||
object_id_hash = hashlib.sha1(str.encode(object_id_str))
|
||||
object_id = plasma.ObjectID(object_id_hash.digest())
|
||||
object_id_out = plasma.ObjectID(hashlib.sha1(str.encode(f"out-{object_id_str}")).digest())
|
||||
input_frame = plasma_client.get(object_id, timeout_ms=0)
|
||||
|
||||
if input_frame is plasma.ObjectNotAvailable:
|
||||
continue
|
||||
|
||||
# detect and put the output in the plasma store
|
||||
start.value = datetime.datetime.now().timestamp()
|
||||
plasma_client.put(object_detector.detect_raw(input_frame), object_id_out)
|
||||
duration = datetime.datetime.now().timestamp()-start.value
|
||||
start.value = 0.0
|
||||
|
||||
avg_speed.value = (avg_speed.value*9 + duration)/10
|
||||
|
||||
class EdgeTPUProcess():
|
||||
def __init__(self):
|
||||
self.detection_queue = mp.SimpleQueue()
|
||||
self.avg_inference_speed = mp.Value('d', 0.01)
|
||||
self.detection_start = mp.Value('d', 0.0)
|
||||
self.detect_process = None
|
||||
self.start_or_restart()
|
||||
|
||||
def start_or_restart(self):
|
||||
self.detection_start.value = 0.0
|
||||
if (not self.detect_process is None) and self.detect_process.is_alive():
|
||||
self.detect_process.terminate()
|
||||
print("Waiting for detection process to exit gracefully...")
|
||||
self.detect_process.join(timeout=30)
|
||||
if self.detect_process.exitcode is None:
|
||||
print("Detection process didnt exit. Force killing...")
|
||||
self.detect_process.kill()
|
||||
self.detect_process.join()
|
||||
self.detect_process = mp.Process(target=run_detector, args=(self.detection_queue, self.avg_inference_speed, self.detection_start))
|
||||
self.detect_process.daemon = True
|
||||
self.detect_process.start()
|
||||
|
||||
class RemoteObjectDetector():
|
||||
def __init__(self, name, labels, detection_queue):
|
||||
self.labels = load_labels(labels)
|
||||
self.name = name
|
||||
self.fps = EventsPerSecond()
|
||||
self.plasma_client = plasma.connect("/tmp/plasma")
|
||||
self.detection_queue = detection_queue
|
||||
|
||||
def detect(self, tensor_input, threshold=.4):
|
||||
detections = []
|
||||
|
||||
now = f"{self.name}-{str(datetime.datetime.now().timestamp())}"
|
||||
object_id_frame = plasma.ObjectID(hashlib.sha1(str.encode(now)).digest())
|
||||
object_id_detections = plasma.ObjectID(hashlib.sha1(str.encode(f"out-{now}")).digest())
|
||||
self.plasma_client.put(tensor_input, object_id_frame)
|
||||
self.detection_queue.put(now)
|
||||
raw_detections = self.plasma_client.get(object_id_detections, timeout_ms=10000)
|
||||
|
||||
if raw_detections is plasma.ObjectNotAvailable:
|
||||
self.plasma_client.delete([object_id_frame])
|
||||
return detections
|
||||
|
||||
for d in raw_detections:
|
||||
if d[1] < threshold:
|
||||
break
|
||||
detections.append((
|
||||
self.labels[int(d[0])],
|
||||
float(d[1]),
|
||||
(d[2], d[3], d[4], d[5])
|
||||
))
|
||||
self.plasma_client.delete([object_id_frame, object_id_detections])
|
||||
self.fps.update()
|
||||
return detections
|
||||
@@ -1,79 +0,0 @@
|
||||
import cv2
|
||||
import imutils
|
||||
import numpy as np
|
||||
|
||||
class MotionDetector():
|
||||
def __init__(self, frame_shape, mask, resize_factor=4):
|
||||
self.resize_factor = resize_factor
|
||||
self.motion_frame_size = (int(frame_shape[0]/resize_factor), int(frame_shape[1]/resize_factor))
|
||||
self.avg_frame = np.zeros(self.motion_frame_size, np.float)
|
||||
self.avg_delta = np.zeros(self.motion_frame_size, np.float)
|
||||
self.motion_frame_count = 0
|
||||
self.frame_counter = 0
|
||||
resized_mask = cv2.resize(mask, dsize=(self.motion_frame_size[1], self.motion_frame_size[0]), interpolation=cv2.INTER_LINEAR)
|
||||
self.mask = np.where(resized_mask==[0])
|
||||
|
||||
def detect(self, frame):
|
||||
motion_boxes = []
|
||||
|
||||
# resize frame
|
||||
resized_frame = cv2.resize(frame, dsize=(self.motion_frame_size[1], self.motion_frame_size[0]), interpolation=cv2.INTER_LINEAR)
|
||||
|
||||
# convert to grayscale
|
||||
gray = cv2.cvtColor(resized_frame, cv2.COLOR_BGR2GRAY)
|
||||
|
||||
# mask frame
|
||||
gray[self.mask] = [255]
|
||||
|
||||
# it takes ~30 frames to establish a baseline
|
||||
# dont bother looking for motion
|
||||
if self.frame_counter < 30:
|
||||
self.frame_counter += 1
|
||||
else:
|
||||
# compare to average
|
||||
frameDelta = cv2.absdiff(gray, cv2.convertScaleAbs(self.avg_frame))
|
||||
|
||||
# compute the average delta over the past few frames
|
||||
# the alpha value can be modified to configure how sensitive the motion detection is.
|
||||
# higher values mean the current frame impacts the delta a lot, and a single raindrop may
|
||||
# register as motion, too low and a fast moving person wont be detected as motion
|
||||
# this also assumes that a person is in the same location across more than a single frame
|
||||
cv2.accumulateWeighted(frameDelta, self.avg_delta, 0.2)
|
||||
|
||||
# compute the threshold image for the current frame
|
||||
current_thresh = cv2.threshold(frameDelta, 25, 255, cv2.THRESH_BINARY)[1]
|
||||
|
||||
# black out everything in the avg_delta where there isnt motion in the current frame
|
||||
avg_delta_image = cv2.convertScaleAbs(self.avg_delta)
|
||||
avg_delta_image[np.where(current_thresh==[0])] = [0]
|
||||
|
||||
# then look for deltas above the threshold, but only in areas where there is a delta
|
||||
# in the current frame. this prevents deltas from previous frames from being included
|
||||
thresh = cv2.threshold(avg_delta_image, 25, 255, cv2.THRESH_BINARY)[1]
|
||||
|
||||
# dilate the thresholded image to fill in holes, then find contours
|
||||
# on thresholded image
|
||||
thresh = cv2.dilate(thresh, None, iterations=2)
|
||||
cnts = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
|
||||
cnts = imutils.grab_contours(cnts)
|
||||
|
||||
# loop over the contours
|
||||
for c in cnts:
|
||||
# if the contour is big enough, count it as motion
|
||||
contour_area = cv2.contourArea(c)
|
||||
if contour_area > 100:
|
||||
x, y, w, h = cv2.boundingRect(c)
|
||||
motion_boxes.append((x*self.resize_factor, y*self.resize_factor, (x+w)*self.resize_factor, (y+h)*self.resize_factor))
|
||||
|
||||
if len(motion_boxes) > 0:
|
||||
self.motion_frame_count += 1
|
||||
# TODO: this really depends on FPS
|
||||
if self.motion_frame_count >= 10:
|
||||
# only average in the current frame if the difference persists for at least 3 frames
|
||||
cv2.accumulateWeighted(gray, self.avg_frame, 0.2)
|
||||
else:
|
||||
# when no motion, just keep averaging the frames together
|
||||
cv2.accumulateWeighted(gray, self.avg_frame, 0.2)
|
||||
self.motion_frame_count = 0
|
||||
|
||||
return motion_boxes
|
||||
33
frigate/mqtt.py
Normal file
33
frigate/mqtt.py
Normal file
@@ -0,0 +1,33 @@
|
||||
import json
|
||||
import threading
|
||||
|
||||
class MqttObjectPublisher(threading.Thread):
|
||||
def __init__(self, client, topic_prefix, objects_parsed, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self.client = client
|
||||
self.topic_prefix = topic_prefix
|
||||
self.objects_parsed = objects_parsed
|
||||
self._detected_objects = detected_objects
|
||||
|
||||
def run(self):
|
||||
last_sent_payload = ""
|
||||
while True:
|
||||
|
||||
# initialize the payload
|
||||
payload = {}
|
||||
|
||||
# wait until objects have been parsed
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.wait()
|
||||
|
||||
# add all the person scores in detected objects
|
||||
detected_objects = self._detected_objects.copy()
|
||||
person_score = sum([obj['score'] for obj in detected_objects if obj['name'] == 'person'])
|
||||
# if the person score is more than 100, set person to ON
|
||||
payload['person'] = 'ON' if int(person_score*100) > 100 else 'OFF'
|
||||
|
||||
# send message for objects if different
|
||||
new_payload = json.dumps(payload, sort_keys=True)
|
||||
if new_payload != last_sent_payload:
|
||||
last_sent_payload = new_payload
|
||||
self.client.publish(self.topic_prefix+'/objects', new_payload, retain=False)
|
||||
112
frigate/object_detection.py
Normal file
112
frigate/object_detection.py
Normal file
@@ -0,0 +1,112 @@
|
||||
import datetime
|
||||
import time
|
||||
import cv2
|
||||
import threading
|
||||
import numpy as np
|
||||
from edgetpu.detection.engine import DetectionEngine
|
||||
from . util import tonumpyarray
|
||||
|
||||
# Path to frozen detection graph. This is the actual model that is used for the object detection.
|
||||
PATH_TO_CKPT = '/frozen_inference_graph.pb'
|
||||
# List of the strings that is used to add correct label for each box.
|
||||
PATH_TO_LABELS = '/label_map.pbtext'
|
||||
|
||||
# Function to read labels from text files.
|
||||
def ReadLabelFile(file_path):
|
||||
with open(file_path, 'r') as f:
|
||||
lines = f.readlines()
|
||||
ret = {}
|
||||
for line in lines:
|
||||
pair = line.strip().split(maxsplit=1)
|
||||
ret[int(pair[0])] = pair[1].strip()
|
||||
return ret
|
||||
|
||||
class PreppedQueueProcessor(threading.Thread):
|
||||
def __init__(self, cameras, prepped_frame_queue):
|
||||
|
||||
threading.Thread.__init__(self)
|
||||
self.cameras = cameras
|
||||
self.prepped_frame_queue = prepped_frame_queue
|
||||
|
||||
# Load the edgetpu engine and labels
|
||||
self.engine = DetectionEngine(PATH_TO_CKPT)
|
||||
self.labels = ReadLabelFile(PATH_TO_LABELS)
|
||||
|
||||
def run(self):
|
||||
# process queue...
|
||||
while True:
|
||||
frame = self.prepped_frame_queue.get()
|
||||
|
||||
# Actual detection.
|
||||
objects = self.engine.DetectWithInputTensor(frame['frame'], threshold=frame['region_threshold'], top_k=3)
|
||||
# parse and pass detected objects back to the camera
|
||||
parsed_objects = []
|
||||
for obj in objects:
|
||||
box = obj.bounding_box.flatten().tolist()
|
||||
parsed_objects.append({
|
||||
'frame_time': frame['frame_time'],
|
||||
'name': str(self.labels[obj.label_id]),
|
||||
'score': float(obj.score),
|
||||
'xmin': int((box[0] * frame['region_size']) + frame['region_x_offset']),
|
||||
'ymin': int((box[1] * frame['region_size']) + frame['region_y_offset']),
|
||||
'xmax': int((box[2] * frame['region_size']) + frame['region_x_offset']),
|
||||
'ymax': int((box[3] * frame['region_size']) + frame['region_y_offset'])
|
||||
})
|
||||
self.cameras[frame['camera_name']].add_objects(parsed_objects)
|
||||
|
||||
|
||||
# should this be a region class?
|
||||
class FramePrepper(threading.Thread):
|
||||
def __init__(self, camera_name, shared_frame, frame_time, frame_ready,
|
||||
frame_lock,
|
||||
region_size, region_x_offset, region_y_offset, region_threshold,
|
||||
prepped_frame_queue):
|
||||
|
||||
threading.Thread.__init__(self)
|
||||
self.camera_name = camera_name
|
||||
self.shared_frame = shared_frame
|
||||
self.frame_time = frame_time
|
||||
self.frame_ready = frame_ready
|
||||
self.frame_lock = frame_lock
|
||||
self.region_size = region_size
|
||||
self.region_x_offset = region_x_offset
|
||||
self.region_y_offset = region_y_offset
|
||||
self.region_threshold = region_threshold
|
||||
self.prepped_frame_queue = prepped_frame_queue
|
||||
|
||||
def run(self):
|
||||
frame_time = 0.0
|
||||
while True:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
|
||||
with self.frame_ready:
|
||||
# if there isnt a frame ready for processing or it is old, wait for a new frame
|
||||
if self.frame_time.value == frame_time or (now - self.frame_time.value) > 0.5:
|
||||
self.frame_ready.wait()
|
||||
|
||||
# make a copy of the cropped frame
|
||||
with self.frame_lock:
|
||||
cropped_frame = self.shared_frame[self.region_y_offset:self.region_y_offset+self.region_size, self.region_x_offset:self.region_x_offset+self.region_size].copy()
|
||||
frame_time = self.frame_time.value
|
||||
|
||||
# convert to RGB
|
||||
cropped_frame_rgb = cv2.cvtColor(cropped_frame, cv2.COLOR_BGR2RGB)
|
||||
# Resize to 300x300 if needed
|
||||
if cropped_frame_rgb.shape != (300, 300, 3):
|
||||
cropped_frame_rgb = cv2.resize(cropped_frame_rgb, dsize=(300, 300), interpolation=cv2.INTER_LINEAR)
|
||||
# Expand dimensions since the model expects images to have shape: [1, 300, 300, 3]
|
||||
frame_expanded = np.expand_dims(cropped_frame_rgb, axis=0)
|
||||
|
||||
# add the frame to the queue
|
||||
if not self.prepped_frame_queue.full():
|
||||
self.prepped_frame_queue.put({
|
||||
'camera_name': self.camera_name,
|
||||
'frame_time': frame_time,
|
||||
'frame': frame_expanded.flatten().copy(),
|
||||
'region_size': self.region_size,
|
||||
'region_threshold': self.region_threshold,
|
||||
'region_x_offset': self.region_x_offset,
|
||||
'region_y_offset': self.region_y_offset
|
||||
})
|
||||
else:
|
||||
print("queue full. moving on")
|
||||
@@ -1,146 +0,0 @@
|
||||
import json
|
||||
import hashlib
|
||||
import datetime
|
||||
import time
|
||||
import copy
|
||||
import cv2
|
||||
import threading
|
||||
import numpy as np
|
||||
from collections import Counter, defaultdict
|
||||
import itertools
|
||||
import pyarrow.plasma as plasma
|
||||
import matplotlib.pyplot as plt
|
||||
from frigate.util import draw_box_with_label, PlasmaManager
|
||||
from frigate.edgetpu import load_labels
|
||||
|
||||
PATH_TO_LABELS = '/labelmap.txt'
|
||||
|
||||
LABELS = load_labels(PATH_TO_LABELS)
|
||||
cmap = plt.cm.get_cmap('tab10', len(LABELS.keys()))
|
||||
|
||||
COLOR_MAP = {}
|
||||
for key, val in LABELS.items():
|
||||
COLOR_MAP[val] = tuple(int(round(255 * c)) for c in cmap(key)[:3])
|
||||
|
||||
class TrackedObjectProcessor(threading.Thread):
|
||||
def __init__(self, config, client, topic_prefix, tracked_objects_queue):
|
||||
threading.Thread.__init__(self)
|
||||
self.config = config
|
||||
self.client = client
|
||||
self.topic_prefix = topic_prefix
|
||||
self.tracked_objects_queue = tracked_objects_queue
|
||||
self.camera_data = defaultdict(lambda: {
|
||||
'best_objects': {},
|
||||
'object_status': defaultdict(lambda: defaultdict(lambda: 'OFF')),
|
||||
'tracked_objects': {},
|
||||
'current_frame': np.zeros((720,1280,3), np.uint8),
|
||||
'object_id': None
|
||||
})
|
||||
self.plasma_client = PlasmaManager()
|
||||
|
||||
def get_best(self, camera, label):
|
||||
if label in self.camera_data[camera]['best_objects']:
|
||||
return self.camera_data[camera]['best_objects'][label]['frame']
|
||||
else:
|
||||
return None
|
||||
|
||||
def get_current_frame(self, camera):
|
||||
return self.camera_data[camera]['current_frame']
|
||||
|
||||
def run(self):
|
||||
while True:
|
||||
camera, frame_time, tracked_objects = self.tracked_objects_queue.get()
|
||||
|
||||
config = self.config[camera]
|
||||
best_objects = self.camera_data[camera]['best_objects']
|
||||
current_object_status = self.camera_data[camera]['object_status']
|
||||
self.camera_data[camera]['tracked_objects'] = tracked_objects
|
||||
|
||||
###
|
||||
# Draw tracked objects on the frame
|
||||
###
|
||||
current_frame = self.plasma_client.get(f"{camera}{frame_time}")
|
||||
|
||||
if not current_frame is plasma.ObjectNotAvailable:
|
||||
# draw the bounding boxes on the frame
|
||||
for obj in tracked_objects.values():
|
||||
thickness = 2
|
||||
color = COLOR_MAP[obj['label']]
|
||||
|
||||
if obj['frame_time'] != frame_time:
|
||||
thickness = 1
|
||||
color = (255,0,0)
|
||||
|
||||
# draw the bounding boxes on the frame
|
||||
box = obj['box']
|
||||
draw_box_with_label(current_frame, box[0], box[1], box[2], box[3], obj['label'], f"{int(obj['score']*100)}% {int(obj['area'])}", thickness=thickness, color=color)
|
||||
# draw the regions on the frame
|
||||
region = obj['region']
|
||||
cv2.rectangle(current_frame, (region[0], region[1]), (region[2], region[3]), (0,255,0), 1)
|
||||
|
||||
if config['snapshots']['show_timestamp']:
|
||||
time_to_show = datetime.datetime.fromtimestamp(frame_time).strftime("%m/%d/%Y %H:%M:%S")
|
||||
cv2.putText(current_frame, time_to_show, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, fontScale=.8, color=(255, 255, 255), thickness=2)
|
||||
|
||||
###
|
||||
# Set the current frame as ready
|
||||
###
|
||||
self.camera_data[camera]['current_frame'] = current_frame
|
||||
|
||||
# store the object id, so you can delete it at the next loop
|
||||
previous_object_id = f"{camera}{frame_time}"
|
||||
if not previous_object_id is None:
|
||||
self.plasma_client.delete(f"{camera}{frame_time}")
|
||||
self.camera_data[camera]['object_id'] = f"{camera}{frame_time}"
|
||||
|
||||
###
|
||||
# Maintain the highest scoring recent object and frame for each label
|
||||
###
|
||||
for obj in tracked_objects.values():
|
||||
# if the object wasn't seen on the current frame, skip it
|
||||
if obj['frame_time'] != frame_time:
|
||||
continue
|
||||
if obj['label'] in best_objects:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# if the object is a higher score than the current best score
|
||||
# or the current object is more than 1 minute old, use the new object
|
||||
if obj['score'] > best_objects[obj['label']]['score'] or (now - best_objects[obj['label']]['frame_time']) > 60:
|
||||
obj['frame'] = np.copy(self.camera_data[camera]['current_frame'])
|
||||
best_objects[obj['label']] = obj
|
||||
else:
|
||||
obj['frame'] = np.copy(self.camera_data[camera]['current_frame'])
|
||||
best_objects[obj['label']] = obj
|
||||
|
||||
###
|
||||
# Report over MQTT
|
||||
###
|
||||
# count objects with more than 2 entries in history by type
|
||||
obj_counter = Counter()
|
||||
for obj in tracked_objects.values():
|
||||
if len(obj['history']) > 1:
|
||||
obj_counter[obj['label']] += 1
|
||||
|
||||
# report on detected objects
|
||||
for obj_name, count in obj_counter.items():
|
||||
new_status = 'ON' if count > 0 else 'OFF'
|
||||
if new_status != current_object_status[obj_name]:
|
||||
current_object_status[obj_name] = new_status
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}", new_status, retain=False)
|
||||
# send the best snapshot over mqtt
|
||||
best_frame = cv2.cvtColor(best_objects[obj_name]['frame'], cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
if ret:
|
||||
jpg_bytes = jpg.tobytes()
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}/snapshot", jpg_bytes, retain=True)
|
||||
|
||||
# expire any objects that are ON and no longer detected
|
||||
expired_objects = [obj_name for obj_name, status in current_object_status.items() if status == 'ON' and not obj_name in obj_counter]
|
||||
for obj_name in expired_objects:
|
||||
current_object_status[obj_name] = 'OFF'
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}", 'OFF', retain=False)
|
||||
# send updated snapshot over mqtt
|
||||
best_frame = cv2.cvtColor(best_objects[obj_name]['frame'], cv2.COLOR_RGB2BGR)
|
||||
ret, jpg = cv2.imencode('.jpg', best_frame)
|
||||
if ret:
|
||||
jpg_bytes = jpg.tobytes()
|
||||
self.client.publish(f"{self.topic_prefix}/{camera}/{obj_name}/snapshot", jpg_bytes, retain=True)
|
||||
@@ -2,158 +2,89 @@ import time
|
||||
import datetime
|
||||
import threading
|
||||
import cv2
|
||||
import itertools
|
||||
import copy
|
||||
import numpy as np
|
||||
import multiprocessing as mp
|
||||
from collections import defaultdict
|
||||
from scipy.spatial import distance as dist
|
||||
from frigate.util import draw_box_with_label, calculate_region
|
||||
|
||||
class ObjectTracker():
|
||||
def __init__(self, max_disappeared):
|
||||
self.tracked_objects = {}
|
||||
self.disappeared = {}
|
||||
self.max_disappeared = max_disappeared
|
||||
class ObjectCleaner(threading.Thread):
|
||||
def __init__(self, objects_parsed, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self._objects_parsed = objects_parsed
|
||||
self._detected_objects = detected_objects
|
||||
|
||||
def register(self, index, obj):
|
||||
id = f"{obj['frame_time']}-{index}"
|
||||
obj['id'] = id
|
||||
obj['top_score'] = obj['score']
|
||||
self.add_history(obj)
|
||||
self.tracked_objects[id] = obj
|
||||
self.disappeared[id] = 0
|
||||
def run(self):
|
||||
while True:
|
||||
|
||||
def deregister(self, id):
|
||||
del self.tracked_objects[id]
|
||||
del self.disappeared[id]
|
||||
# wait a bit before checking for expired frames
|
||||
time.sleep(0.2)
|
||||
|
||||
def update(self, id, new_obj):
|
||||
self.disappeared[id] = 0
|
||||
self.tracked_objects[id].update(new_obj)
|
||||
self.add_history(self.tracked_objects[id])
|
||||
if self.tracked_objects[id]['score'] > self.tracked_objects[id]['top_score']:
|
||||
self.tracked_objects[id]['top_score'] = self.tracked_objects[id]['score']
|
||||
# expire the objects that are more than 1 second old
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# look for the first object found within the last second
|
||||
# (newest objects are appended to the end)
|
||||
detected_objects = self._detected_objects.copy()
|
||||
|
||||
def add_history(self, obj):
|
||||
entry = {
|
||||
'score': obj['score'],
|
||||
'box': obj['box'],
|
||||
'region': obj['region'],
|
||||
'centroid': obj['centroid'],
|
||||
'frame_time': obj['frame_time']
|
||||
}
|
||||
if 'history' in obj:
|
||||
obj['history'].append(entry)
|
||||
else:
|
||||
obj['history'] = [entry]
|
||||
num_to_delete = 0
|
||||
for obj in detected_objects:
|
||||
if now-obj['frame_time']<2:
|
||||
break
|
||||
num_to_delete += 1
|
||||
if num_to_delete > 0:
|
||||
del self._detected_objects[:num_to_delete]
|
||||
|
||||
def match_and_update(self, frame_time, new_objects):
|
||||
# group by name
|
||||
new_object_groups = defaultdict(lambda: [])
|
||||
for obj in new_objects:
|
||||
new_object_groups[obj[0]].append({
|
||||
'label': obj[0],
|
||||
'score': obj[1],
|
||||
'box': obj[2],
|
||||
'area': obj[3],
|
||||
'region': obj[4],
|
||||
'frame_time': frame_time
|
||||
})
|
||||
# notify that parsed objects were changed
|
||||
with self._objects_parsed:
|
||||
self._objects_parsed.notify_all()
|
||||
|
||||
# update any tracked objects with labels that are not
|
||||
# seen in the current objects and deregister if needed
|
||||
for obj in list(self.tracked_objects.values()):
|
||||
if not obj['label'] in new_object_groups:
|
||||
if self.disappeared[obj['id']] >= self.max_disappeared:
|
||||
self.deregister(obj['id'])
|
||||
else:
|
||||
self.disappeared[obj['id']] += 1
|
||||
|
||||
if len(new_objects) == 0:
|
||||
return
|
||||
# Maintains the frame and person with the highest score from the most recent
|
||||
# motion event
|
||||
class BestPersonFrame(threading.Thread):
|
||||
def __init__(self, objects_parsed, recent_frames, detected_objects):
|
||||
threading.Thread.__init__(self)
|
||||
self.objects_parsed = objects_parsed
|
||||
self.recent_frames = recent_frames
|
||||
self.detected_objects = detected_objects
|
||||
self.best_person = None
|
||||
self.best_frame = None
|
||||
|
||||
# track objects for each label type
|
||||
for label, group in new_object_groups.items():
|
||||
current_objects = [o for o in self.tracked_objects.values() if o['label'] == label]
|
||||
current_ids = [o['id'] for o in current_objects]
|
||||
current_centroids = np.array([o['centroid'] for o in current_objects])
|
||||
def run(self):
|
||||
while True:
|
||||
|
||||
# compute centroids of new objects
|
||||
for obj in group:
|
||||
centroid_x = int((obj['box'][0]+obj['box'][2]) / 2.0)
|
||||
centroid_y = int((obj['box'][1]+obj['box'][3]) / 2.0)
|
||||
obj['centroid'] = (centroid_x, centroid_y)
|
||||
# wait until objects have been parsed
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.wait()
|
||||
|
||||
if len(current_objects) == 0:
|
||||
for index, obj in enumerate(group):
|
||||
self.register(index, obj)
|
||||
return
|
||||
# make a copy of detected objects
|
||||
detected_objects = self.detected_objects.copy()
|
||||
detected_people = [obj for obj in detected_objects if obj['name'] == 'person']
|
||||
|
||||
new_centroids = np.array([o['centroid'] for o in group])
|
||||
# get the highest scoring person
|
||||
new_best_person = max(detected_people, key=lambda x:x['score'], default=self.best_person)
|
||||
|
||||
# compute the distance between each pair of tracked
|
||||
# centroids and new centroids, respectively -- our
|
||||
# goal will be to match each new centroid to an existing
|
||||
# object centroid
|
||||
D = dist.cdist(current_centroids, new_centroids)
|
||||
|
||||
# in order to perform this matching we must (1) find the
|
||||
# smallest value in each row and then (2) sort the row
|
||||
# indexes based on their minimum values so that the row
|
||||
# with the smallest value is at the *front* of the index
|
||||
# list
|
||||
rows = D.min(axis=1).argsort()
|
||||
|
||||
# next, we perform a similar process on the columns by
|
||||
# finding the smallest value in each column and then
|
||||
# sorting using the previously computed row index list
|
||||
cols = D.argmin(axis=1)[rows]
|
||||
|
||||
# in order to determine if we need to update, register,
|
||||
# or deregister an object we need to keep track of which
|
||||
# of the rows and column indexes we have already examined
|
||||
usedRows = set()
|
||||
usedCols = set()
|
||||
|
||||
# loop over the combination of the (row, column) index
|
||||
# tuples
|
||||
for (row, col) in zip(rows, cols):
|
||||
# if we have already examined either the row or
|
||||
# column value before, ignore it
|
||||
if row in usedRows or col in usedCols:
|
||||
# if there isnt a person, continue
|
||||
if new_best_person is None:
|
||||
continue
|
||||
|
||||
# otherwise, grab the object ID for the current row,
|
||||
# set its new centroid, and reset the disappeared
|
||||
# counter
|
||||
objectID = current_ids[row]
|
||||
self.update(objectID, group[col])
|
||||
|
||||
# indicate that we have examined each of the row and
|
||||
# column indexes, respectively
|
||||
usedRows.add(row)
|
||||
usedCols.add(col)
|
||||
|
||||
# compute the column index we have NOT yet examined
|
||||
unusedRows = set(range(0, D.shape[0])).difference(usedRows)
|
||||
unusedCols = set(range(0, D.shape[1])).difference(usedCols)
|
||||
|
||||
# in the event that the number of object centroids is
|
||||
# equal or greater than the number of input centroids
|
||||
# we need to check and see if some of these objects have
|
||||
# potentially disappeared
|
||||
if D.shape[0] >= D.shape[1]:
|
||||
for row in unusedRows:
|
||||
id = current_ids[row]
|
||||
|
||||
if self.disappeared[id] >= self.max_disappeared:
|
||||
self.deregister(id)
|
||||
# if there is no current best_person
|
||||
if self.best_person is None:
|
||||
self.best_person = new_best_person
|
||||
# if there is already a best_person
|
||||
else:
|
||||
self.disappeared[id] += 1
|
||||
# if the number of input centroids is greater
|
||||
# than the number of existing object centroids we need to
|
||||
# register each new input centroid as a trackable object
|
||||
else:
|
||||
for col in unusedCols:
|
||||
self.register(col, group[col])
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# if the new best person is a higher score than the current best person
|
||||
# or the current person is more than 1 minute old, use the new best person
|
||||
if new_best_person['score'] > self.best_person['score'] or (now - self.best_person['frame_time']) > 60:
|
||||
self.best_person = new_best_person
|
||||
|
||||
# make a copy of the recent frames
|
||||
recent_frames = self.recent_frames.copy()
|
||||
|
||||
if not self.best_person is None and self.best_person['frame_time'] in recent_frames:
|
||||
best_frame = recent_frames[self.best_person['frame_time']]
|
||||
best_frame = cv2.cvtColor(best_frame, cv2.COLOR_BGR2RGB)
|
||||
# draw the bounding box on the frame
|
||||
color = (255,0,0)
|
||||
cv2.rectangle(best_frame, (self.best_person['xmin'], self.best_person['ymin']),
|
||||
(self.best_person['xmax'], self.best_person['ymax']),
|
||||
color, 2)
|
||||
|
||||
# convert back to BGR
|
||||
self.best_frame = cv2.cvtColor(best_frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
184
frigate/util.py
Executable file → Normal file
184
frigate/util.py
Executable file → Normal file
@@ -1,183 +1,5 @@
|
||||
import datetime
|
||||
import time
|
||||
import signal
|
||||
import traceback
|
||||
import collections
|
||||
import numpy as np
|
||||
import cv2
|
||||
import threading
|
||||
import matplotlib.pyplot as plt
|
||||
import hashlib
|
||||
import pyarrow.plasma as plasma
|
||||
|
||||
def draw_box_with_label(frame, x_min, y_min, x_max, y_max, label, info, thickness=2, color=None, position='ul'):
|
||||
if color is None:
|
||||
color = (0,0,255)
|
||||
display_text = "{}: {}".format(label, info)
|
||||
cv2.rectangle(frame, (x_min, y_min), (x_max, y_max), color, thickness)
|
||||
font_scale = 0.5
|
||||
font = cv2.FONT_HERSHEY_SIMPLEX
|
||||
# get the width and height of the text box
|
||||
size = cv2.getTextSize(display_text, font, fontScale=font_scale, thickness=2)
|
||||
text_width = size[0][0]
|
||||
text_height = size[0][1]
|
||||
line_height = text_height + size[1]
|
||||
# set the text start position
|
||||
if position == 'ul':
|
||||
text_offset_x = x_min
|
||||
text_offset_y = 0 if y_min < line_height else y_min - (line_height+8)
|
||||
elif position == 'ur':
|
||||
text_offset_x = x_max - (text_width+8)
|
||||
text_offset_y = 0 if y_min < line_height else y_min - (line_height+8)
|
||||
elif position == 'bl':
|
||||
text_offset_x = x_min
|
||||
text_offset_y = y_max
|
||||
elif position == 'br':
|
||||
text_offset_x = x_max - (text_width+8)
|
||||
text_offset_y = y_max
|
||||
# make the coords of the box with a small padding of two pixels
|
||||
textbox_coords = ((text_offset_x, text_offset_y), (text_offset_x + text_width + 2, text_offset_y + line_height))
|
||||
cv2.rectangle(frame, textbox_coords[0], textbox_coords[1], color, cv2.FILLED)
|
||||
cv2.putText(frame, display_text, (text_offset_x, text_offset_y + line_height - 3), font, fontScale=font_scale, color=(0, 0, 0), thickness=2)
|
||||
|
||||
def calculate_region(frame_shape, xmin, ymin, xmax, ymax, multiplier=2):
|
||||
# size is larger than longest edge
|
||||
size = int(max(xmax-xmin, ymax-ymin)*multiplier)
|
||||
# if the size is too big to fit in the frame
|
||||
if size > min(frame_shape[0], frame_shape[1]):
|
||||
size = min(frame_shape[0], frame_shape[1])
|
||||
|
||||
# x_offset is midpoint of bounding box minus half the size
|
||||
x_offset = int((xmax-xmin)/2.0+xmin-size/2.0)
|
||||
# if outside the image
|
||||
if x_offset < 0:
|
||||
x_offset = 0
|
||||
elif x_offset > (frame_shape[1]-size):
|
||||
x_offset = (frame_shape[1]-size)
|
||||
|
||||
# y_offset is midpoint of bounding box minus half the size
|
||||
y_offset = int((ymax-ymin)/2.0+ymin-size/2.0)
|
||||
# if outside the image
|
||||
if y_offset < 0:
|
||||
y_offset = 0
|
||||
elif y_offset > (frame_shape[0]-size):
|
||||
y_offset = (frame_shape[0]-size)
|
||||
|
||||
return (x_offset, y_offset, x_offset+size, y_offset+size)
|
||||
|
||||
def intersection(box_a, box_b):
|
||||
return (
|
||||
max(box_a[0], box_b[0]),
|
||||
max(box_a[1], box_b[1]),
|
||||
min(box_a[2], box_b[2]),
|
||||
min(box_a[3], box_b[3])
|
||||
)
|
||||
|
||||
def area(box):
|
||||
return (box[2]-box[0] + 1)*(box[3]-box[1] + 1)
|
||||
|
||||
def intersection_over_union(box_a, box_b):
|
||||
# determine the (x, y)-coordinates of the intersection rectangle
|
||||
intersect = intersection(box_a, box_b)
|
||||
|
||||
# compute the area of intersection rectangle
|
||||
inter_area = max(0, intersect[2] - intersect[0] + 1) * max(0, intersect[3] - intersect[1] + 1)
|
||||
|
||||
if inter_area == 0:
|
||||
return 0.0
|
||||
|
||||
# compute the area of both the prediction and ground-truth
|
||||
# rectangles
|
||||
box_a_area = (box_a[2] - box_a[0] + 1) * (box_a[3] - box_a[1] + 1)
|
||||
box_b_area = (box_b[2] - box_b[0] + 1) * (box_b[3] - box_b[1] + 1)
|
||||
|
||||
# compute the intersection over union by taking the intersection
|
||||
# area and dividing it by the sum of prediction + ground-truth
|
||||
# areas - the interesection area
|
||||
iou = inter_area / float(box_a_area + box_b_area - inter_area)
|
||||
|
||||
# return the intersection over union value
|
||||
return iou
|
||||
|
||||
def clipped(obj, frame_shape):
|
||||
# if the object is within 5 pixels of the region border, and the region is not on the edge
|
||||
# consider the object to be clipped
|
||||
box = obj[2]
|
||||
region = obj[4]
|
||||
if ((region[0] > 5 and box[0]-region[0] <= 5) or
|
||||
(region[1] > 5 and box[1]-region[1] <= 5) or
|
||||
(frame_shape[1]-region[2] > 5 and region[2]-box[2] <= 5) or
|
||||
(frame_shape[0]-region[3] > 5 and region[3]-box[3] <= 5)):
|
||||
return True
|
||||
else:
|
||||
return False
|
||||
|
||||
class EventsPerSecond:
|
||||
def __init__(self, max_events=1000):
|
||||
self._start = None
|
||||
self._max_events = max_events
|
||||
self._timestamps = []
|
||||
|
||||
def start(self):
|
||||
self._start = datetime.datetime.now().timestamp()
|
||||
|
||||
def update(self):
|
||||
self._timestamps.append(datetime.datetime.now().timestamp())
|
||||
# truncate the list when it goes 100 over the max_size
|
||||
if len(self._timestamps) > self._max_events+100:
|
||||
self._timestamps = self._timestamps[(1-self._max_events):]
|
||||
|
||||
def eps(self, last_n_seconds=10):
|
||||
# compute the (approximate) events in the last n seconds
|
||||
now = datetime.datetime.now().timestamp()
|
||||
seconds = min(now-self._start, last_n_seconds)
|
||||
return len([t for t in self._timestamps if t > (now-last_n_seconds)]) / seconds
|
||||
|
||||
def print_stack(sig, frame):
|
||||
traceback.print_stack(frame)
|
||||
|
||||
def listen():
|
||||
signal.signal(signal.SIGUSR1, print_stack)
|
||||
|
||||
class PlasmaManager:
|
||||
def __init__(self):
|
||||
self.connect()
|
||||
|
||||
def connect(self):
|
||||
while True:
|
||||
try:
|
||||
self.plasma_client = plasma.connect("/tmp/plasma")
|
||||
return
|
||||
except:
|
||||
print(f"TrackedObjectProcessor: unable to connect plasma client")
|
||||
time.sleep(10)
|
||||
|
||||
def get(self, name, timeout_ms=0):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
try:
|
||||
return self.plasma_client.get(object_id, timeout_ms=timeout_ms)
|
||||
except:
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
|
||||
def put(self, name, obj):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
try:
|
||||
self.plasma_client.put(obj, object_id)
|
||||
return
|
||||
except Exception as e:
|
||||
print(f"Failed to put in plasma: {e}")
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
|
||||
def delete(self, name):
|
||||
object_id = plasma.ObjectID(hashlib.sha1(str.encode(name)).digest())
|
||||
while True:
|
||||
try:
|
||||
self.plasma_client.delete([object_id])
|
||||
return
|
||||
except:
|
||||
self.connect()
|
||||
time.sleep(1)
|
||||
# convert shared memory array into numpy array
|
||||
def tonumpyarray(mp_arr):
|
||||
return np.frombuffer(mp_arr.get_obj(), dtype=np.uint8)
|
||||
593
frigate/video.py
Executable file → Normal file
593
frigate/video.py
Executable file → Normal file
@@ -2,373 +2,302 @@ import os
|
||||
import time
|
||||
import datetime
|
||||
import cv2
|
||||
import queue
|
||||
import threading
|
||||
import ctypes
|
||||
import pyarrow.plasma as plasma
|
||||
import multiprocessing as mp
|
||||
import subprocess as sp
|
||||
import numpy as np
|
||||
import copy
|
||||
import itertools
|
||||
import json
|
||||
from collections import defaultdict
|
||||
from frigate.util import draw_box_with_label, area, calculate_region, clipped, intersection_over_union, intersection, EventsPerSecond, listen, PlasmaManager
|
||||
from frigate.objects import ObjectTracker
|
||||
from frigate.edgetpu import RemoteObjectDetector
|
||||
from frigate.motion import MotionDetector
|
||||
from . util import tonumpyarray
|
||||
from . object_detection import FramePrepper
|
||||
from . objects import ObjectCleaner, BestPersonFrame
|
||||
from . mqtt import MqttObjectPublisher
|
||||
|
||||
def get_frame_shape(source):
|
||||
ffprobe_cmd = " ".join([
|
||||
'ffprobe',
|
||||
'-v',
|
||||
'panic',
|
||||
'-show_error',
|
||||
'-show_streams',
|
||||
'-of',
|
||||
'json',
|
||||
'"'+source+'"'
|
||||
])
|
||||
print(ffprobe_cmd)
|
||||
p = sp.Popen(ffprobe_cmd, stdout=sp.PIPE, shell=True)
|
||||
(output, err) = p.communicate()
|
||||
p_status = p.wait()
|
||||
info = json.loads(output)
|
||||
print(info)
|
||||
# fetch the frames as fast a possible and store current frame in a shared memory array
|
||||
def fetch_frames(shared_arr, shared_frame_time, frame_lock, frame_ready, frame_shape, rtsp_url):
|
||||
# convert shared memory array into numpy and shape into image array
|
||||
arr = tonumpyarray(shared_arr).reshape(frame_shape)
|
||||
|
||||
video_info = [s for s in info['streams'] if s['codec_type'] == 'video'][0]
|
||||
# start the video capture
|
||||
video = cv2.VideoCapture()
|
||||
video.open(rtsp_url)
|
||||
print("Opening the RTSP Url...")
|
||||
# keep the buffer small so we minimize old data
|
||||
video.set(cv2.CAP_PROP_BUFFERSIZE,1)
|
||||
|
||||
if video_info['height'] != 0 and video_info['width'] != 0:
|
||||
return (video_info['height'], video_info['width'], 3)
|
||||
bad_frame_counter = 0
|
||||
while True:
|
||||
# check if the video stream is still open, and reopen if needed
|
||||
if not video.isOpened():
|
||||
success = video.open(rtsp_url)
|
||||
if not success:
|
||||
time.sleep(1)
|
||||
continue
|
||||
# grab the frame, but dont decode it yet
|
||||
ret = video.grab()
|
||||
# snapshot the time the frame was grabbed
|
||||
frame_time = datetime.datetime.now()
|
||||
if ret:
|
||||
# go ahead and decode the current frame
|
||||
ret, frame = video.retrieve()
|
||||
if ret:
|
||||
# Lock access and update frame
|
||||
with frame_lock:
|
||||
arr[:] = frame
|
||||
shared_frame_time.value = frame_time.timestamp()
|
||||
# Notify with the condition that a new frame is ready
|
||||
with frame_ready:
|
||||
frame_ready.notify_all()
|
||||
bad_frame_counter = 0
|
||||
else:
|
||||
print("Unable to decode frame")
|
||||
bad_frame_counter += 1
|
||||
else:
|
||||
print("Unable to grab a frame")
|
||||
bad_frame_counter += 1
|
||||
|
||||
# fallback to using opencv if ffprobe didnt succeed
|
||||
video = cv2.VideoCapture(source)
|
||||
if bad_frame_counter > 100:
|
||||
video.release()
|
||||
|
||||
video.release()
|
||||
|
||||
# Stores 2 seconds worth of frames when motion is detected so they can be used for other threads
|
||||
class FrameTracker(threading.Thread):
|
||||
def __init__(self, shared_frame, frame_time, frame_ready, frame_lock, recent_frames):
|
||||
threading.Thread.__init__(self)
|
||||
self.shared_frame = shared_frame
|
||||
self.frame_time = frame_time
|
||||
self.frame_ready = frame_ready
|
||||
self.frame_lock = frame_lock
|
||||
self.recent_frames = recent_frames
|
||||
|
||||
def run(self):
|
||||
frame_time = 0.0
|
||||
while True:
|
||||
now = datetime.datetime.now().timestamp()
|
||||
# wait for a frame
|
||||
with self.frame_ready:
|
||||
# if there isnt a frame ready for processing or it is old, wait for a signal
|
||||
if self.frame_time.value == frame_time or (now - self.frame_time.value) > 0.5:
|
||||
self.frame_ready.wait()
|
||||
|
||||
# lock and make a copy of the frame
|
||||
with self.frame_lock:
|
||||
frame = self.shared_frame.copy()
|
||||
frame_time = self.frame_time.value
|
||||
|
||||
# add the frame to recent frames
|
||||
self.recent_frames[frame_time] = frame
|
||||
|
||||
# delete any old frames
|
||||
stored_frame_times = list(self.recent_frames.keys())
|
||||
for k in stored_frame_times:
|
||||
if (now - k) > 2:
|
||||
del self.recent_frames[k]
|
||||
|
||||
def get_frame_shape(rtsp_url):
|
||||
# capture a single frame and check the frame shape so the correct array
|
||||
# size can be allocated in memory
|
||||
video = cv2.VideoCapture(rtsp_url)
|
||||
ret, frame = video.read()
|
||||
frame_shape = frame.shape
|
||||
video.release()
|
||||
return frame_shape
|
||||
|
||||
def get_ffmpeg_input(ffmpeg_input):
|
||||
frigate_vars = {k: v for k, v in os.environ.items() if k.startswith('FRIGATE_')}
|
||||
return ffmpeg_input.format(**frigate_vars)
|
||||
def get_rtsp_url(rtsp_config):
|
||||
if (rtsp_config['password'].startswith('$')):
|
||||
rtsp_config['password'] = os.getenv(rtsp_config['password'][1:])
|
||||
return 'rtsp://{}:{}@{}:{}{}'.format(rtsp_config['user'],
|
||||
rtsp_config['password'], rtsp_config['host'], rtsp_config['port'],
|
||||
rtsp_config['path'])
|
||||
|
||||
def filtered(obj, objects_to_track, object_filters, mask):
|
||||
object_name = obj[0]
|
||||
|
||||
if not object_name in objects_to_track:
|
||||
return True
|
||||
|
||||
if object_name in object_filters:
|
||||
obj_settings = object_filters[object_name]
|
||||
|
||||
# if the min area is larger than the
|
||||
# detected object, don't add it to detected objects
|
||||
if obj_settings.get('min_area',-1) > obj[3]:
|
||||
return True
|
||||
|
||||
# if the detected object is larger than the
|
||||
# max area, don't add it to detected objects
|
||||
if obj_settings.get('max_area', 24000000) < obj[3]:
|
||||
return True
|
||||
|
||||
# if the score is lower than the threshold, skip
|
||||
if obj_settings.get('threshold', 0) > obj[1]:
|
||||
return True
|
||||
|
||||
# compute the coordinates of the object and make sure
|
||||
# the location isnt outside the bounds of the image (can happen from rounding)
|
||||
y_location = min(int(obj[2][3]), len(mask)-1)
|
||||
x_location = min(int((obj[2][2]-obj[2][0])/2.0)+obj[2][0], len(mask[0])-1)
|
||||
|
||||
# if the object is in a masked location, don't add it to detected objects
|
||||
if mask[y_location][x_location] == [0]:
|
||||
return True
|
||||
|
||||
return False
|
||||
|
||||
def create_tensor_input(frame, region):
|
||||
cropped_frame = frame[region[1]:region[3], region[0]:region[2]]
|
||||
|
||||
# Resize to 300x300 if needed
|
||||
if cropped_frame.shape != (300, 300, 3):
|
||||
cropped_frame = cv2.resize(cropped_frame, dsize=(300, 300), interpolation=cv2.INTER_LINEAR)
|
||||
|
||||
# Expand dimensions since the model expects images to have shape: [1, 300, 300, 3]
|
||||
return np.expand_dims(cropped_frame, axis=0)
|
||||
|
||||
def start_or_restart_ffmpeg(ffmpeg_cmd, frame_size, ffmpeg_process=None):
|
||||
if not ffmpeg_process is None:
|
||||
print("Terminating the existing ffmpeg process...")
|
||||
ffmpeg_process.terminate()
|
||||
try:
|
||||
print("Waiting for ffmpeg to exit gracefully...")
|
||||
ffmpeg_process.communicate(timeout=30)
|
||||
except sp.TimeoutExpired:
|
||||
print("FFmpeg didnt exit. Force killing...")
|
||||
ffmpeg_process.kill()
|
||||
ffmpeg_process.communicate()
|
||||
ffmpeg_process = None
|
||||
|
||||
print("Creating ffmpeg process...")
|
||||
print(" ".join(ffmpeg_cmd))
|
||||
process = sp.Popen(ffmpeg_cmd, stdout = sp.PIPE, stdin = sp.DEVNULL, bufsize=frame_size*10, start_new_session=True)
|
||||
return process
|
||||
|
||||
class CameraCapture(threading.Thread):
|
||||
def __init__(self, name, ffmpeg_process, frame_shape, frame_queue, take_frame, fps):
|
||||
class CameraWatchdog(threading.Thread):
|
||||
def __init__(self, camera):
|
||||
threading.Thread.__init__(self)
|
||||
self.name = name
|
||||
self.frame_shape = frame_shape
|
||||
self.frame_size = frame_shape[0] * frame_shape[1] * frame_shape[2]
|
||||
self.frame_queue = frame_queue
|
||||
self.take_frame = take_frame
|
||||
self.fps = fps
|
||||
self.plasma_client = PlasmaManager()
|
||||
self.ffmpeg_process = ffmpeg_process
|
||||
self.camera = camera
|
||||
|
||||
def run(self):
|
||||
frame_num = 0
|
||||
|
||||
while True:
|
||||
if self.ffmpeg_process.poll() != None:
|
||||
print(f"{self.name}: ffmpeg process is not running. exiting capture thread...")
|
||||
break
|
||||
# wait a bit before checking
|
||||
time.sleep(60)
|
||||
|
||||
frame_bytes = self.ffmpeg_process.stdout.read(self.frame_size)
|
||||
frame_time = datetime.datetime.now().timestamp()
|
||||
if (datetime.datetime.now().timestamp() - self.camera.shared_frame_time.value) > 2:
|
||||
print("last frame is more than 2 seconds old, restarting camera capture...")
|
||||
self.camera.start_or_restart_capture()
|
||||
time.sleep(5)
|
||||
|
||||
if len(frame_bytes) == 0:
|
||||
print(f"{self.name}: ffmpeg didnt return a frame. something is wrong.")
|
||||
continue
|
||||
class Camera:
|
||||
def __init__(self, name, config, prepped_frame_queue, mqtt_client, mqtt_prefix):
|
||||
self.name = name
|
||||
self.config = config
|
||||
self.detected_objects = []
|
||||
self.recent_frames = {}
|
||||
self.rtsp_url = get_rtsp_url(self.config['rtsp'])
|
||||
self.regions = self.config['regions']
|
||||
self.frame_shape = get_frame_shape(self.rtsp_url)
|
||||
self.mqtt_client = mqtt_client
|
||||
self.mqtt_topic_prefix = '{}/{}'.format(mqtt_prefix, self.name)
|
||||
|
||||
frame_num += 1
|
||||
if (frame_num % self.take_frame) != 0:
|
||||
continue
|
||||
# compute the flattened array length from the shape of the frame
|
||||
flat_array_length = self.frame_shape[0] * self.frame_shape[1] * self.frame_shape[2]
|
||||
# create shared array for storing the full frame image data
|
||||
self.shared_frame_array = mp.Array(ctypes.c_uint8, flat_array_length)
|
||||
# create shared value for storing the frame_time
|
||||
self.shared_frame_time = mp.Value('d', 0.0)
|
||||
# Lock to control access to the frame
|
||||
self.frame_lock = mp.Lock()
|
||||
# Condition for notifying that a new frame is ready
|
||||
self.frame_ready = mp.Condition()
|
||||
# Condition for notifying that objects were parsed
|
||||
self.objects_parsed = mp.Condition()
|
||||
|
||||
# put the frame in the plasma store
|
||||
self.plasma_client.put(f"{self.name}{frame_time}",
|
||||
np
|
||||
.frombuffer(frame_bytes, np.uint8)
|
||||
.reshape(self.frame_shape)
|
||||
)
|
||||
# add to the queue
|
||||
self.frame_queue.put(frame_time)
|
||||
# shape current frame so it can be treated as a numpy image
|
||||
self.shared_frame_np = tonumpyarray(self.shared_frame_array).reshape(self.frame_shape)
|
||||
|
||||
self.fps.update()
|
||||
self.capture_process = None
|
||||
|
||||
def track_camera(name, config, global_objects_config, frame_queue, frame_shape, detection_queue, detected_objects_queue, fps, skipped_fps, detection_fps, read_start):
|
||||
print(f"Starting process for {name}: {os.getpid()}")
|
||||
listen()
|
||||
|
||||
# Merge the tracked object config with the global config
|
||||
camera_objects_config = config.get('objects', {})
|
||||
# combine tracked objects lists
|
||||
objects_to_track = set().union(global_objects_config.get('track', ['person', 'car', 'truck']), camera_objects_config.get('track', []))
|
||||
# merge object filters
|
||||
global_object_filters = global_objects_config.get('filters', {})
|
||||
camera_object_filters = camera_objects_config.get('filters', {})
|
||||
objects_with_config = set().union(global_object_filters.keys(), camera_object_filters.keys())
|
||||
object_filters = {}
|
||||
for obj in objects_with_config:
|
||||
object_filters[obj] = {**global_object_filters.get(obj, {}), **camera_object_filters.get(obj, {})}
|
||||
|
||||
expected_fps = config['fps']
|
||||
|
||||
frame = np.zeros(frame_shape, np.uint8)
|
||||
|
||||
# load in the mask for object detection
|
||||
if 'mask' in config:
|
||||
mask = cv2.imread("/config/{}".format(config['mask']), cv2.IMREAD_GRAYSCALE)
|
||||
else:
|
||||
mask = None
|
||||
|
||||
if mask is None:
|
||||
mask = np.zeros((frame_shape[0], frame_shape[1], 1), np.uint8)
|
||||
mask[:] = 255
|
||||
|
||||
motion_detector = MotionDetector(frame_shape, mask, resize_factor=6)
|
||||
object_detector = RemoteObjectDetector(name, '/labelmap.txt', detection_queue)
|
||||
|
||||
object_tracker = ObjectTracker(10)
|
||||
|
||||
plasma_client = PlasmaManager()
|
||||
frame_num = 0
|
||||
avg_wait = 0.0
|
||||
fps_tracker = EventsPerSecond()
|
||||
skipped_fps_tracker = EventsPerSecond()
|
||||
fps_tracker.start()
|
||||
skipped_fps_tracker.start()
|
||||
object_detector.fps.start()
|
||||
while True:
|
||||
read_start.value = datetime.datetime.now().timestamp()
|
||||
frame_time = frame_queue.get()
|
||||
duration = datetime.datetime.now().timestamp()-read_start.value
|
||||
read_start.value = 0.0
|
||||
avg_wait = (avg_wait*99+duration)/100
|
||||
|
||||
fps_tracker.update()
|
||||
fps.value = fps_tracker.eps()
|
||||
detection_fps.value = object_detector.fps.eps()
|
||||
|
||||
# Get frame from plasma store
|
||||
frame = plasma_client.get(f"{name}{frame_time}")
|
||||
|
||||
if frame is plasma.ObjectNotAvailable:
|
||||
skipped_fps_tracker.update()
|
||||
skipped_fps.value = skipped_fps_tracker.eps()
|
||||
continue
|
||||
|
||||
# look for motion
|
||||
motion_boxes = motion_detector.detect(frame)
|
||||
|
||||
# skip object detection if we are below the min_fps and wait time is less than half the average
|
||||
if frame_num > 100 and fps.value < expected_fps-1 and duration < 0.5*avg_wait:
|
||||
skipped_fps_tracker.update()
|
||||
skipped_fps.value = skipped_fps_tracker.eps()
|
||||
plasma_client.delete(f"{name}{frame_time}")
|
||||
continue
|
||||
|
||||
skipped_fps.value = skipped_fps_tracker.eps()
|
||||
|
||||
tracked_objects = object_tracker.tracked_objects.values()
|
||||
|
||||
# merge areas of motion that intersect with a known tracked object into a single area to look at
|
||||
areas_of_interest = []
|
||||
used_motion_boxes = []
|
||||
for obj in tracked_objects:
|
||||
x_min, y_min, x_max, y_max = obj['box']
|
||||
for m_index, motion_box in enumerate(motion_boxes):
|
||||
if area(intersection(obj['box'], motion_box))/area(motion_box) > .5:
|
||||
used_motion_boxes.append(m_index)
|
||||
x_min = min(obj['box'][0], motion_box[0])
|
||||
y_min = min(obj['box'][1], motion_box[1])
|
||||
x_max = max(obj['box'][2], motion_box[2])
|
||||
y_max = max(obj['box'][3], motion_box[3])
|
||||
areas_of_interest.append((x_min, y_min, x_max, y_max))
|
||||
unused_motion_boxes = set(range(0, len(motion_boxes))).difference(used_motion_boxes)
|
||||
|
||||
# compute motion regions
|
||||
motion_regions = [calculate_region(frame_shape, motion_boxes[i][0], motion_boxes[i][1], motion_boxes[i][2], motion_boxes[i][3], 1.2)
|
||||
for i in unused_motion_boxes]
|
||||
|
||||
# compute tracked object regions
|
||||
object_regions = [calculate_region(frame_shape, a[0], a[1], a[2], a[3], 1.2)
|
||||
for a in areas_of_interest]
|
||||
|
||||
# merge regions with high IOU
|
||||
merged_regions = motion_regions+object_regions
|
||||
while True:
|
||||
max_iou = 0.0
|
||||
max_indices = None
|
||||
region_indices = range(len(merged_regions))
|
||||
for a, b in itertools.combinations(region_indices, 2):
|
||||
iou = intersection_over_union(merged_regions[a], merged_regions[b])
|
||||
if iou > max_iou:
|
||||
max_iou = iou
|
||||
max_indices = (a, b)
|
||||
if max_iou > 0.1:
|
||||
a = merged_regions[max_indices[0]]
|
||||
b = merged_regions[max_indices[1]]
|
||||
merged_regions.append(calculate_region(frame_shape,
|
||||
min(a[0], b[0]),
|
||||
min(a[1], b[1]),
|
||||
max(a[2], b[2]),
|
||||
max(a[3], b[3]),
|
||||
1
|
||||
# for each region, create a separate thread to resize the region and prep for detection
|
||||
self.detection_prep_threads = []
|
||||
for region in self.config['regions']:
|
||||
# set a default threshold of 0.5 if not defined
|
||||
if not 'threshold' in region:
|
||||
region['threshold'] = 0.5
|
||||
if not isinstance(region['threshold'], float):
|
||||
print('Threshold is not a float. Setting to 0.5 default.')
|
||||
region['threshold'] = 0.5
|
||||
self.detection_prep_threads.append(FramePrepper(
|
||||
self.name,
|
||||
self.shared_frame_np,
|
||||
self.shared_frame_time,
|
||||
self.frame_ready,
|
||||
self.frame_lock,
|
||||
region['size'], region['x_offset'], region['y_offset'], region['threshold'],
|
||||
prepped_frame_queue
|
||||
))
|
||||
del merged_regions[max(max_indices[0], max_indices[1])]
|
||||
del merged_regions[min(max_indices[0], max_indices[1])]
|
||||
|
||||
# start a thread to store recent motion frames for processing
|
||||
self.frame_tracker = FrameTracker(self.shared_frame_np, self.shared_frame_time,
|
||||
self.frame_ready, self.frame_lock, self.recent_frames)
|
||||
self.frame_tracker.start()
|
||||
|
||||
# start a thread to store the highest scoring recent person frame
|
||||
self.best_person_frame = BestPersonFrame(self.objects_parsed, self.recent_frames, self.detected_objects)
|
||||
self.best_person_frame.start()
|
||||
|
||||
# start a thread to expire objects from the detected objects list
|
||||
self.object_cleaner = ObjectCleaner(self.objects_parsed, self.detected_objects)
|
||||
self.object_cleaner.start()
|
||||
|
||||
# start a thread to publish object scores (currently only person)
|
||||
mqtt_publisher = MqttObjectPublisher(self.mqtt_client, self.mqtt_topic_prefix, self.objects_parsed, self.detected_objects)
|
||||
mqtt_publisher.start()
|
||||
|
||||
# create a watchdog thread for capture process
|
||||
self.watchdog = CameraWatchdog(self)
|
||||
|
||||
# load in the mask for person detection
|
||||
if 'mask' in self.config:
|
||||
self.mask = cv2.imread("/config/{}".format(self.config['mask']), cv2.IMREAD_GRAYSCALE)
|
||||
else:
|
||||
self.mask = np.zeros((self.frame_shape[0], self.frame_shape[1], 1), np.uint8)
|
||||
self.mask[:] = 255
|
||||
|
||||
|
||||
def start_or_restart_capture(self):
|
||||
if not self.capture_process is None:
|
||||
print("Terminating the existing capture process...")
|
||||
self.capture_process.terminate()
|
||||
del self.capture_process
|
||||
self.capture_process = None
|
||||
|
||||
# create the process to capture frames from the RTSP stream and store in a shared array
|
||||
print("Creating a new capture process...")
|
||||
self.capture_process = mp.Process(target=fetch_frames, args=(self.shared_frame_array,
|
||||
self.shared_frame_time, self.frame_lock, self.frame_ready, self.frame_shape, self.rtsp_url))
|
||||
self.capture_process.daemon = True
|
||||
print("Starting a new capture process...")
|
||||
self.capture_process.start()
|
||||
|
||||
def start(self):
|
||||
self.start_or_restart_capture()
|
||||
# start the object detection prep threads
|
||||
for detection_prep_thread in self.detection_prep_threads:
|
||||
detection_prep_thread.start()
|
||||
self.watchdog.start()
|
||||
|
||||
def join(self):
|
||||
self.capture_process.join()
|
||||
|
||||
def get_capture_pid(self):
|
||||
return self.capture_process.pid
|
||||
|
||||
def add_objects(self, objects):
|
||||
if len(objects) == 0:
|
||||
return
|
||||
|
||||
for obj in objects:
|
||||
if obj['name'] == 'person':
|
||||
person_area = (obj['xmax']-obj['xmin'])*(obj['ymax']-obj['ymin'])
|
||||
# find the matching region
|
||||
region = None
|
||||
for r in self.regions:
|
||||
if (
|
||||
obj['xmin'] >= r['x_offset'] and
|
||||
obj['ymin'] >= r['y_offset'] and
|
||||
obj['xmax'] <= r['x_offset']+r['size'] and
|
||||
obj['ymax'] <= r['y_offset']+r['size']
|
||||
):
|
||||
region = r
|
||||
break
|
||||
|
||||
# resize regions and detect
|
||||
detections = []
|
||||
for region in merged_regions:
|
||||
|
||||
tensor_input = create_tensor_input(frame, region)
|
||||
|
||||
region_detections = object_detector.detect(tensor_input)
|
||||
|
||||
for d in region_detections:
|
||||
box = d[2]
|
||||
size = region[2]-region[0]
|
||||
x_min = int((box[1] * size) + region[0])
|
||||
y_min = int((box[0] * size) + region[1])
|
||||
x_max = int((box[3] * size) + region[0])
|
||||
y_max = int((box[2] * size) + region[1])
|
||||
det = (d[0],
|
||||
d[1],
|
||||
(x_min, y_min, x_max, y_max),
|
||||
(x_max-x_min)*(y_max-y_min),
|
||||
region)
|
||||
if filtered(det, objects_to_track, object_filters, mask):
|
||||
# if the min person area is larger than the
|
||||
# detected person, don't add it to detected objects
|
||||
if region and region['min_person_area'] > person_area:
|
||||
continue
|
||||
detections.append(det)
|
||||
|
||||
#########
|
||||
# merge objects, check for clipped objects and look again up to N times
|
||||
#########
|
||||
refining = True
|
||||
refine_count = 0
|
||||
while refining and refine_count < 4:
|
||||
refining = False
|
||||
# compute the coordinates of the person and make sure
|
||||
# the location isnt outide the bounds of the image (can happen from rounding)
|
||||
y_location = min(int(obj['ymax']), len(self.mask)-1)
|
||||
x_location = min(int((obj['xmax']-obj['xmin'])/2.0), len(self.mask[0])-1)
|
||||
|
||||
# group by name
|
||||
detected_object_groups = defaultdict(lambda: [])
|
||||
for detection in detections:
|
||||
detected_object_groups[detection[0]].append(detection)
|
||||
|
||||
selected_objects = []
|
||||
for group in detected_object_groups.values():
|
||||
|
||||
# apply non-maxima suppression to suppress weak, overlapping bounding boxes
|
||||
boxes = [(o[2][0], o[2][1], o[2][2]-o[2][0], o[2][3]-o[2][1])
|
||||
for o in group]
|
||||
confidences = [o[1] for o in group]
|
||||
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.4)
|
||||
|
||||
for index in idxs:
|
||||
obj = group[index[0]]
|
||||
if clipped(obj, frame_shape):
|
||||
box = obj[2]
|
||||
# calculate a new region that will hopefully get the entire object
|
||||
region = calculate_region(frame_shape,
|
||||
box[0], box[1],
|
||||
box[2], box[3])
|
||||
|
||||
tensor_input = create_tensor_input(frame, region)
|
||||
# run detection on new region
|
||||
refined_detections = object_detector.detect(tensor_input)
|
||||
for d in refined_detections:
|
||||
box = d[2]
|
||||
size = region[2]-region[0]
|
||||
x_min = int((box[1] * size) + region[0])
|
||||
y_min = int((box[0] * size) + region[1])
|
||||
x_max = int((box[3] * size) + region[0])
|
||||
y_max = int((box[2] * size) + region[1])
|
||||
det = (d[0],
|
||||
d[1],
|
||||
(x_min, y_min, x_max, y_max),
|
||||
(x_max-x_min)*(y_max-y_min),
|
||||
region)
|
||||
if filtered(det, objects_to_track, object_filters, mask):
|
||||
# if the person is in a masked location, continue
|
||||
if self.mask[y_location][x_location] == [0]:
|
||||
continue
|
||||
selected_objects.append(det)
|
||||
|
||||
refining = True
|
||||
else:
|
||||
selected_objects.append(obj)
|
||||
self.detected_objects.append(obj)
|
||||
|
||||
# set the detections list to only include top, complete objects
|
||||
# and new detections
|
||||
detections = selected_objects
|
||||
with self.objects_parsed:
|
||||
self.objects_parsed.notify_all()
|
||||
|
||||
def get_best_person(self):
|
||||
return self.best_person_frame.best_frame
|
||||
|
||||
def get_current_frame_with_objects(self):
|
||||
# make a copy of the current detected objects
|
||||
detected_objects = self.detected_objects.copy()
|
||||
# lock and make a copy of the current frame
|
||||
with self.frame_lock:
|
||||
frame = self.shared_frame_np.copy()
|
||||
|
||||
# convert to RGB for drawing
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
|
||||
# draw the bounding boxes on the screen
|
||||
for obj in detected_objects:
|
||||
color = (255,0,0)
|
||||
cv2.rectangle(frame, (obj['xmin'], obj['ymin']),
|
||||
(obj['xmax'], obj['ymax']),
|
||||
color, 2)
|
||||
|
||||
for region in self.regions:
|
||||
color = (255,255,255)
|
||||
cv2.rectangle(frame, (region['x_offset'], region['y_offset']),
|
||||
(region['x_offset']+region['size'], region['y_offset']+region['size']),
|
||||
color, 2)
|
||||
|
||||
# convert back to BGR
|
||||
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
|
||||
|
||||
return frame
|
||||
|
||||
if refining:
|
||||
refine_count += 1
|
||||
|
||||
# now that we have refined our detections, we need to track objects
|
||||
object_tracker.match_and_update(frame_time, detections)
|
||||
|
||||
# add to the queue
|
||||
detected_objects_queue.put((name, frame_time, object_tracker.tracked_objects))
|
||||
|
||||
print(f"{name}: exiting subprocess")
|
||||
Reference in New Issue
Block a user